TuranMart’s data platform now has the essential building blocks of a real production system. PostgreSQL stores operational orders, object storage keeps raw events, Spark and DuckDB transform data at different scales, Kafka and Flink handle streaming workloads, and SQL models produce trusted analytics tables. Yet the business still asks the same painful question every morning: Can we trust today’s numbers? A dashboard can be late because a source export failed. A transformation can run twice and duplicate rows. A machine learning feature table can be stale because its upstream fraud labels did not arrive before the training window closed. At this stage, the problem is no longer only storage or processing. The problem is coordination.
This chapter teaches orchestration as the control plane of the data platform. An orchestrator does not replace databases, object stores, Spark clusters, warehouses, or streaming engines. Instead, it decides what should run, when it should run, what must finish first, how failures should be retried, which historical partitions should be reprocessed, and what evidence proves that the pipeline behaved correctly. Apache Airflow is the main tool because it is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows, and because Airflow workflows are defined in Python as code that can be reviewed, tested, versioned, and deployed.1
GitHub Actions is the delivery tool in this chapter because workflow code must move through the same disciplined path as application code. GitHub describes Actions as a way to automate, customize, and execute software development workflows directly in a repository, including CI/CD.2 For data engineers, this means a pull request can validate DAG imports, run transformation tests, scan for unsafe configuration, and prevent broken orchestration code from reaching production Airflow.
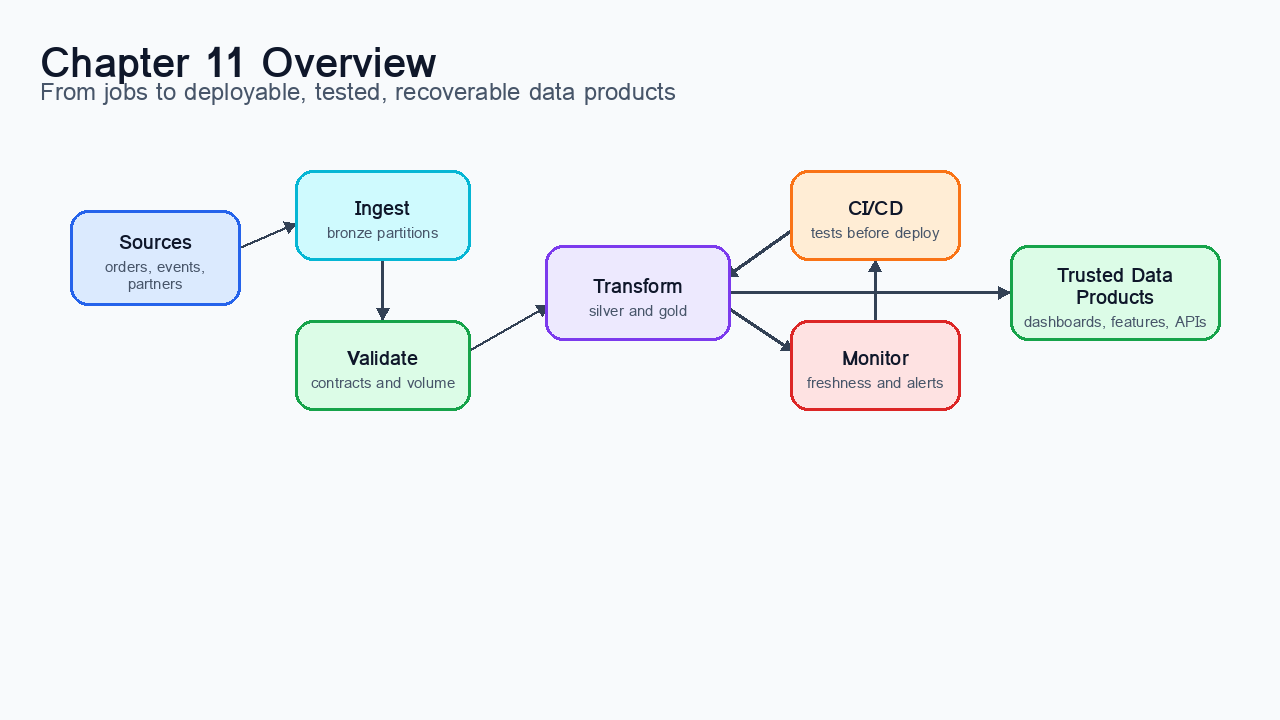
Figure 1:Chapter overview: orchestration turns individual processing jobs into a managed production pipeline with schedules, dependencies, tests, deployment, monitoring, and recovery.
By the end of the chapter, orchestration should no longer feel like “cron with a nicer UI.” It should feel like a professional engineering discipline: the place where data products become operational services.
Learning Objectives¶
By the end of this chapter, you should be able to explain why production data pipelines require orchestration rather than simple scheduling. You should be able to model workflows as Directed Acyclic Graphs, reason about retries and backfills, and describe the main components of an Airflow deployment. You should also be able to compare Airflow, Prefect, Dagster, and Alibaba Cloud DataWorks, then choose an appropriate orchestrator for a concrete team and platform context.
Most importantly, you should be able to design a practical CI/CD workflow for data pipelines. In the guided lab, you will build a production-style TuranMart daily sales pipeline with an Airflow-compatible DAG, deterministic task functions, automated tests, expected outputs, and a GitHub Actions workflow that validates the project before deployment.
| Capability | Practical outcome in this chapter |
|---|---|
| Workflow modeling | Represent a multi-step TuranMart pipeline as tasks, dependencies, schedules, data intervals, and owned data products. |
| Reliability engineering | Use idempotency, retries, timeouts, alerting, and backfills to recover from failures without corrupting outputs. |
| Airflow architecture | Explain the roles of the scheduler, webserver, metadata database, executor, workers, providers, and external compute systems. |
| CI/CD for DAGs | Validate DAG imports, run unit tests, scan configuration, and deploy workflow code through GitHub Actions. |
| Tool selection | Decide when to use Airflow, Prefect, Dagster, Alibaba Cloud DataWorks, or a streaming-first architecture. |
11.1 Why Orchestration Exists: From Jobs to Data Products¶
A data pipeline is rarely one script. A production pipeline is a chain of small promises. The ingestion task promises that today’s raw files have landed. The validation task promises that the files contain the expected columns, volumes, and date ranges. The transformation task promises that business rules were applied consistently. The publishing task promises that downstream users see either a complete new version of the data product or the previous safe version, never a half-written table. Orchestration is the discipline that makes those promises explicit.
A basic scheduler such as cron can start a command at a time of day. That is useful for one independent command, but it cannot easily answer the questions that matter in production. Did the upstream task actually succeed? Which partition failed? Was the failure temporary? Should the system retry now, wait for an external file, or stop and alert a human? If transformation logic was fixed, how do we reprocess the last 30 days without reprocessing the whole year? A workflow orchestrator exists to answer these questions repeatably.
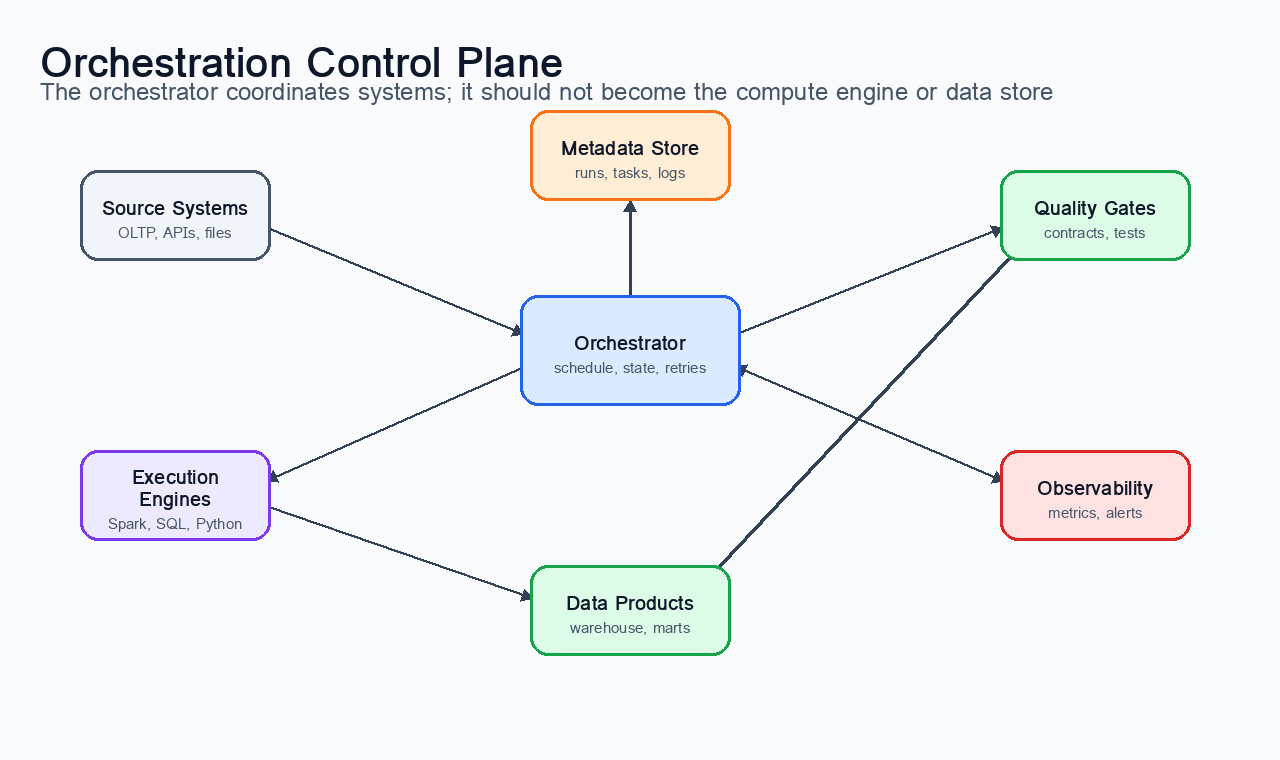
Figure 2:An orchestration control plane coordinates source systems, execution engines, metadata, monitoring, and trusted data products. The orchestrator decides what should run and records what happened; workers and external engines perform the actual compute.
The difference between scheduling and orchestration is easiest to see through operational responsibility. Scheduling asks, “When should this command start?” Orchestration asks a richer set of questions: “What must be true before this task starts? What data interval is this run responsible for? What happens if it fails? What can be retried safely? What evidence proves that the run produced trustworthy output?”
| Concern | Simple scheduler | Production orchestrator |
|---|---|---|
| Start condition | Time-based command execution. | Time, upstream task state, external sensors, dataset availability, manual trigger, or API trigger. |
| Dependency model | Usually implicit in shell scripts. | Explicit graph of tasks and dependencies. |
| Failure behavior | Exit code and separate logs, often handled manually. | Retries, timeouts, alerts, reruns, and recorded task state. |
| Historical processing | Custom scripts and manual loops. | Backfills over well-defined data intervals. |
| Observability | Operating-system logs or email. | Central UI, task history, logs, metrics, lineage integrations, and audit trail. |
| Change management | Manual edits on a server. | Version-controlled workflow code with CI/CD gates. |
A mature data platform treats orchestration metadata as operational data. The metadata database can answer questions such as how long a pipeline usually takes, which task fails most often, which partitions were skipped, and whether freshness objectives are being met. This metadata becomes especially valuable when an organization moves from “the data team knows what happened” to “the business can trust the platform because failures are visible and recoverable.”
For TuranMart, orchestration becomes business-critical when the team begins measuring reliability. The exact targets depend on the company, but the following example shows how concrete operational data turns a vague pipeline into an accountable service.
| Pipeline signal | Example target | Why it matters |
|---|---|---|
Freshness of gold.daily_sales | Available by 07:30 local time on business days | Executives and store managers use morning sales dashboards for operational decisions. |
| Successful scheduled runs | At least 99% of daily scheduled runs complete without manual intervention | Measures whether the platform is dependable enough for routine operations. |
| Mean task duration for transformation | Less than 20 minutes at p95 | Detects performance regressions before they cause missed dashboard deadlines. |
| Data quality failure rate | Less than 1 failed contract per 100 successful partitions | Separates expected data drift from broken upstream systems or code. |
| Recovery time after transient failure | Automatic retry within 15 minutes; human escalation after final failed attempt | Prevents noisy alerts while still surfacing real incidents. |
These targets are not merely management metrics. They shape engineering design. If the freshness target is 07:30 and the slowest upstream API sometimes responds at 07:20, the orchestrator needs sensors, timeouts, fallback behavior, and clear escalation. If backfills are common, tables must be written by partition and tasks must safely overwrite only the intended partition. If data quality failures are frequent, the pipeline should stop before publishing incorrect data rather than making a dashboard look complete but wrong.
11.2 The DAG Paradigm: Dependencies as an Executable Contract¶
Most workflow orchestrators use some form of the Directed Acyclic Graph, usually shortened to DAG. A directed graph has arrows that point from one task to another. If the edge points from extract_orders to validate_orders, validation must wait for extraction to complete. An acyclic graph has no loops. This matters because a workflow with circular dependencies cannot finish: A waits for B, B waits for C, and C waits for A.
In Airflow, a DAG is a model that encapsulates everything needed to execute a workflow, including the schedule, tasks, task dependencies, callbacks, and other operational parameters.3 The DAG does not need to know every internal detail of each task. It needs to know how tasks relate, when runs should be created, how to identify the data interval, and how to record operational state.
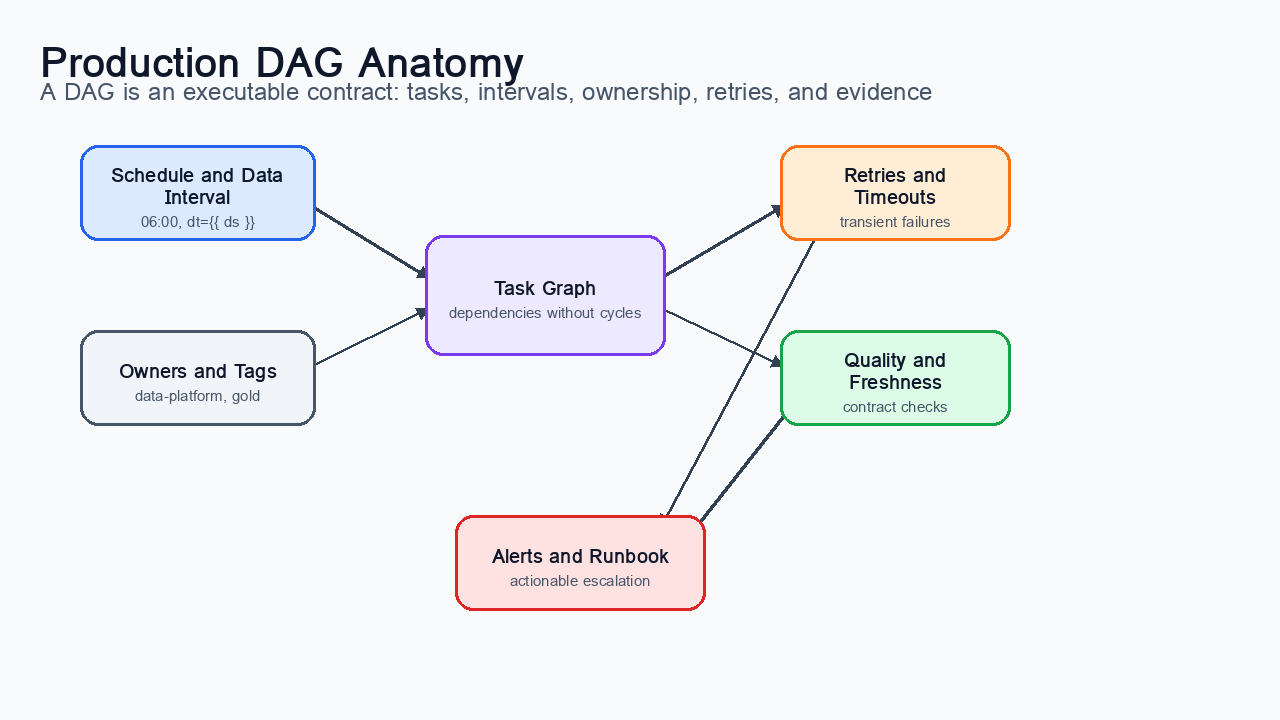
Figure 3:Anatomy of a production DAG: a workflow contract combines tasks, dependencies, data intervals, retry behavior, quality gates, ownership, and alerting.
A good DAG has three qualities. First, it is idempotent, meaning a retry or rerun does not create duplicates or inconsistent output. Second, it is partition-aware, meaning a run knows which logical data interval it is processing, such as 2026-05-02 or 2026-W18. Third, it is observable, meaning each task exposes enough logs, metrics, and data checks to debug failure without guessing.
Definition: A production DAG is not just a diagram of task order. It is an executable contract that declares ownership, schedule, input assumptions, output promises, retry behavior, data interval semantics, and operational evidence.
This contract changes how engineers design pipelines. Instead of writing one large script that downloads data, cleans it, aggregates it, updates a dashboard table, and sends a chat message, the team separates the pipeline into tasks with clear inputs and outputs. The orchestrator then records the state of each task instance for each DAG run. If validation fails, the team knows that the raw landing step succeeded but the quality contract failed. If the gold build fails, the raw and bronze partitions remain available for debugging.
| DAG design question | Strong answer | Weak answer |
|---|---|---|
| What data interval does this run process? | “The Airflow ds value selects exactly one order date partition.” | “The script processes whatever files are in the folder.” |
| What happens on retry? | “The task overwrites only dt={{ ds }} after writing to a temporary path.” | “The task appends rows again and we deduplicate later.” |
| What proves success? | “Output row count, revenue total, required columns, and freshness metric are recorded.” | “The Python process exited with status zero.” |
| Who owns failures? | “The data-platform team owns orchestration; the analytics team owns business rules.” | “Whoever notices the dashboard is broken.” |
| How is a change deployed? | “Pull request, tests, staging backfill, production promotion.” | “Edit the DAG file on the server.” |
For TuranMart, the DAG contract for daily sales might include a daily schedule at 06:00, a freshness target of 07:30, input data under raw/orders/dt={{ ds }}, output data under gold/daily_sales/dt={{ ds }}, two retries for transient extraction tasks, no retry for failed contract checks unless the source is corrected, and a final alert to the on-call data engineer. The key is that these decisions are visible before the pipeline runs.
11.3 Apache Airflow Architecture and Core Concepts¶
Apache Airflow is an open-source platform for developing, scheduling, and monitoring batch-oriented workflows.1 It was created at Airbnb and later became an Apache Software Foundation project. Airflow’s central design idea is workflows as code: workflow definitions are Python files, not manually configured schedules hidden inside a server. The official documentation emphasizes this approach because Python-based workflow definitions make pipelines dynamic, extensible, flexible, versionable, collaborative, and testable.1
Airflow is strongest when workflows are finite and batch-oriented. The documentation is explicit that Airflow is not intended for continuously running, event-driven, or streaming workloads, although it often complements streaming systems such as Kafka.1 This distinction is important. Kafka and Flink handle continuous event processing. Airflow can coordinate batch enrichment, data quality checks, downstream warehouse publishing, model retraining, and periodic backfills around those streaming outputs.
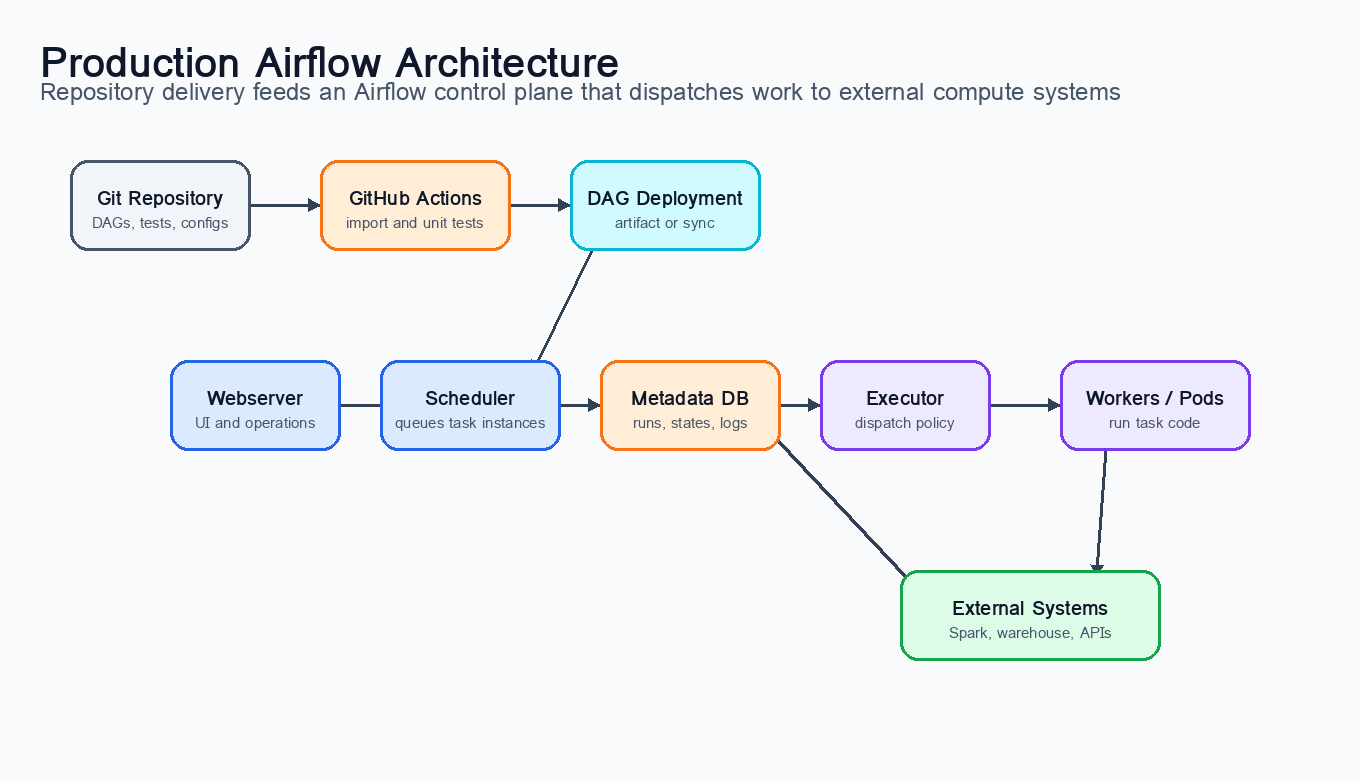
Figure 4:A production Airflow deployment with repository-based delivery. DAG code is validated before deployment, while Airflow’s scheduler, metadata database, executor, workers, and observability stack coordinate runtime execution.
An Airflow installation has a control plane, an execution layer, and external data systems. The control plane decides what should run and records state. The execution layer performs actual work. The data systems hold source and target data; Airflow should coordinate them, not become a database or processing engine itself.
| Component | Responsibility | Production note |
|---|---|---|
| Webserver | Provides the UI for monitoring DAGs, viewing logs, triggering runs, and inspecting task status. | Protect with authentication and role-based access; operational actions should be auditable. |
| Scheduler | Parses DAG files, evaluates schedules and dependencies, and queues tasks for execution. | Scheduler health is critical; monitor parsing time, scheduling delay, and heartbeat. |
| Metadata database | Stores DAG runs, task instances, states, configuration, and operational history. | Use a production database such as PostgreSQL or MySQL; back it up and monitor growth. |
| Executor | Defines how tasks are dispatched to execution resources. | Local execution is useful for development; distributed executors fit larger platforms. |
| Workers or pods | Run task code such as Python functions, SQL commands, Spark submissions, or API calls. | Keep task environments reproducible; avoid hidden dependencies on one server. |
| Provider packages | Supply operators and hooks for external systems. | Pin versions and test provider upgrades because operators are part of the runtime contract. |
| External compute | Runs heavy work in Spark, warehouses, Kubernetes jobs, or APIs. | Keep the scheduler lightweight; submit work rather than performing large computations during DAG parsing. |
Airflow terminology becomes easier when you separate definitions from runtime instances. A DAG represents the workflow definition. An operator is a reusable template for a type of task, such as executing Python code, running a shell command, submitting a Spark job, or querying a database. A task is an instance of an operator inside a DAG. A DAG run is one run of the workflow for a logical date and data interval. A task instance is one task running for one specific DAG run. A hook is a lower-level interface to an external system, and a provider packages operators, hooks, and integrations for a technology ecosystem.3
A practical Airflow DAG for TuranMart might contain the following sequence. The pipeline waits for daily order exports, validates that the row count is within an expected range, writes a bronze partition, runs a Spark transformation to create silver tables, executes SQL models for gold marts, runs data quality checks, and sends a notification. Each step is small enough to debug and rerun independently.
| Task | Input | Output | Safe retry strategy |
|---|---|---|---|
wait_for_orders_export | External file path or API readiness signal | Confirmation that the day’s source data exists | Retry with a timeout; do not create output. |
ingest_orders_bronze | Raw order export | Partitioned bronze file | Write to a temporary path, then atomically promote or overwrite only the target partition. |
validate_bronze_orders | Bronze partition | Quality report | Fail fast if required columns, date range, or volume checks fail. |
transform_orders_silver | Bronze partition | Cleaned silver table partition | Use partition overwrite; avoid appending duplicate rows. |
build_daily_sales_gold | Silver facts and dimensions | Gold sales metrics | Recompute a deterministic partition from source-of-truth inputs. |
publish_success_event | Completed quality checks | Notification or lineage event | Make notification idempotent by including run ID and partition. |
The most important Airflow production rule is simple: do not make the scheduler do heavy work while parsing DAG files. DAG files are imported repeatedly by the scheduler. Heavy top-level imports, network calls, database queries, or large computations can slow down the entire Airflow deployment. Put business logic in modules and call it from tasks at runtime. Keep DAG files focused on orchestration structure.
11.4 Reliability Patterns: Idempotency, Retries, Backfills, and Alerts¶
Orchestration creates reliability only when tasks are designed for recovery. A retry policy cannot save a non-idempotent write. A backfill can repair historical data only if the pipeline knows how to isolate partitions. An alert is useful only when it points to an actionable failure. This section turns the abstract DAG model into practical reliability patterns.
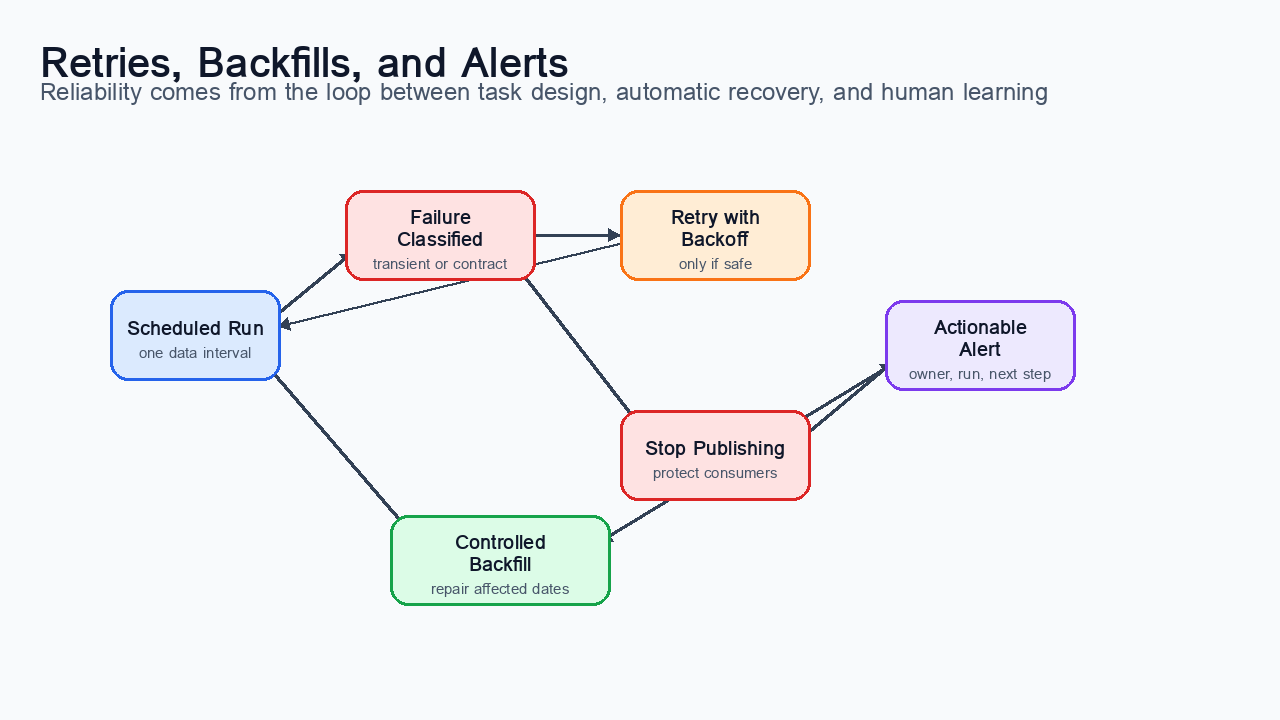
Figure 5:Reliability loop for orchestrated pipelines: tasks fail, retry when the failure is transient, stop on contract violations, backfill corrected intervals, and feed incident learning into future design.
Idempotency means a task can run multiple times for the same data interval without corrupting output. In data engineering, idempotency is usually achieved by deterministic partition writes, atomic replacement, primary keys, merge semantics, or transactions. A task that writes gold/daily_sales/dt=2026-05-02 should produce the same output when rerun with the same input. It should not append a second copy of the same sales rows.
Retries are useful for temporary failures such as network timeouts, rate limits, brief database unavailability, and transient object-storage errors. Retries are harmful when they hide deterministic failures. If a required column is missing from the source file, retrying ten times only delays the alert. A mature retry policy distinguishes between transient infrastructure failures and data contract failures.
| Failure type | Example | Retry? | Preferred response |
|---|---|---|---|
| Transient network | API returns HTTP 503 for two minutes. | Yes, with backoff and timeout. | Retry automatically, then alert after final failure. |
| Late source data | Partner export has not arrived by 06:05. | Yes, but bounded. | Use a sensor or polling task with deadline and escalation. |
| Data contract violation | order_total column is missing. | Usually no. | Fail fast, stop publishing, notify owner of source contract. |
| Deterministic code bug | Transformation raises the same exception every run. | No, after first proof. | Fix code, test, redeploy, and backfill affected intervals. |
| Non-idempotent side effect | Chat notification or external ticket creation. | Carefully. | Include idempotency key, run ID, and partition; avoid duplicate human noise. |
Backfilling is one of the strongest reasons to use an orchestrator. Airflow defines backfill as creating runs for past dates of a DAG, using a DAG, start date, end date, and schedule.4 Airflow also provides controls for reprocessing behavior, maximum active runs during backfill, reverse ordering, and dry runs.4 These controls matter because backfills consume compute, can compete with scheduled runs, and may republish metrics that users already saw.
A responsible backfill begins with a written reason. TuranMart might discover that a promotion discount rule was wrong from May 1 to May 3. The team should fix the transformation, open a pull request, run tests, deploy the corrected DAG, dry-run the backfill, limit concurrency, monitor outputs, and record the incident link in the change log. The command is only the visible part of a larger operational process.
airflow backfill create \
--dag-id turanmart_daily_sales \
--start-date 2026-05-01 \
--end-date 2026-05-03 \
--reprocessing-behavior failed \
--max-active-runs 2Alerting should be designed around action, not anxiety. A message that says “task failed” is weaker than a message that says “build_daily_sales_gold failed for dt=2026-05-02; source validation passed; output was not published; retry is safe after code fix; owner is data-platform.” Alerts should include the DAG ID, task ID, data interval, run ID, failure category, recent log link, owner, severity, and recommended first action.
11.5 CI/CD for Data Pipelines with GitHub Actions¶
A production DAG should be treated as a deployable data product. This means it has a clear owner, a declared schedule, documented inputs and outputs, tests, freshness expectations, alerting rules, and a rollback plan. The orchestration code is only one part of the product; the operational contract around the DAG is equally important.
GitHub Actions supports software workflows defined in repository workflow files. The workflow syntax documentation states that workflow files use YAML syntax, must have a .yml or .yaml extension, and must be stored in the .github/workflows directory.5 The on key defines which events trigger a workflow, including pull requests and path-filtered changes.5 For data engineers, this means repository checks can run only when DAG code, tests, or workflow files change.
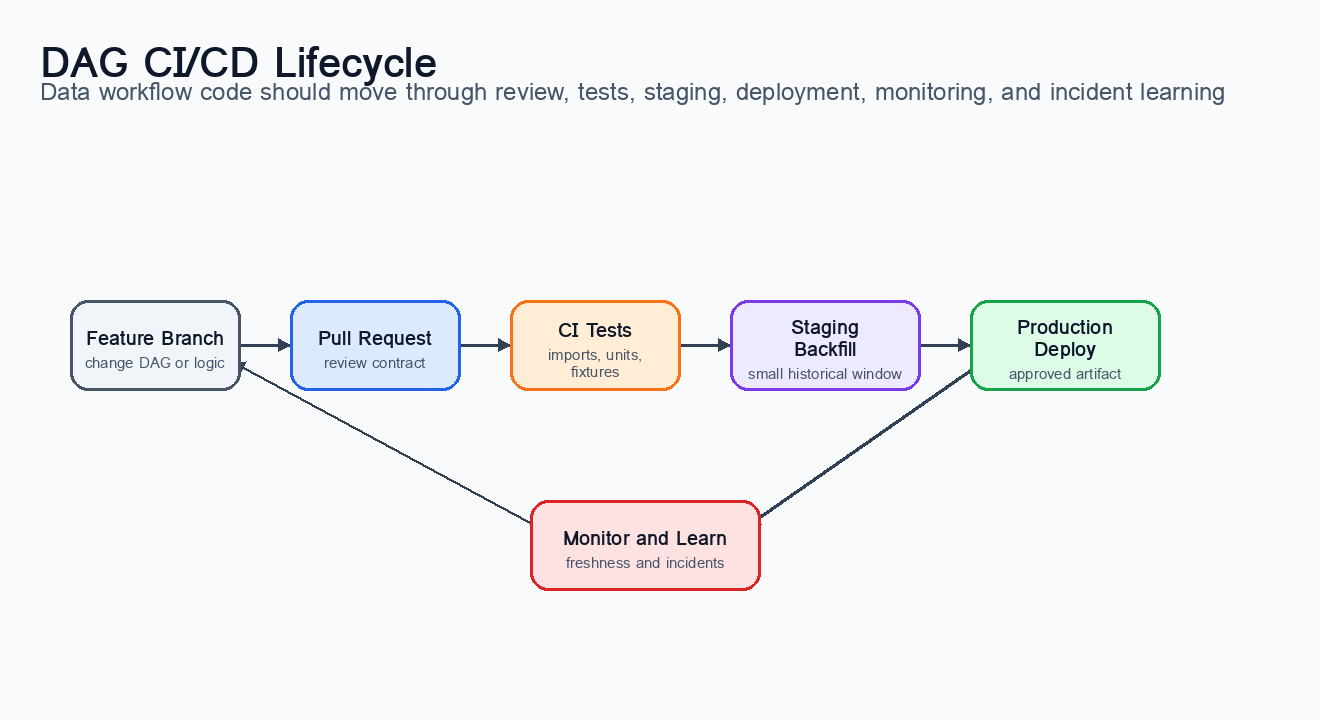
Figure 6:The CI/CD lifecycle for a DAG. Reliable orchestration depends on a feedback loop from business requirements to code, tests, staging backfills, production monitoring, and incident learning.
The delivery pattern below works well for many teams. A developer changes a DAG in a feature branch. The pull request runs automated checks: formatting, static analysis, DAG import tests, unit tests for Python functions, configuration scans, and sometimes lightweight integration tests against sample data. After review, the DAG is deployed to staging, where a small backfill validates data behavior on realistic partitions. Only then is it promoted to production.
| CI/CD stage | What it validates | Example command or check |
|---|---|---|
| Formatting and static checks | The code is readable and follows team conventions. | ruff check dags tests or equivalent linting. |
| DAG import test | Airflow can parse the DAG without runtime import errors. | pytest tests/test_dag_imports.py. |
| Unit tests | Pure Python transformation logic behaves correctly. | pytest tests/test_transformations.py. |
| Configuration scan | Owners, tags, descriptions, schedules, and secrets policy are safe. | Custom test rejecting missing owners or hard-coded credentials. |
| Expected-output test | Sample data produces stable expected output. | Compare generated CSV or Parquet summaries against fixtures. |
| Staging backfill | The DAG can process a small historical window end to end. | airflow backfill create --dag-id .... |
| Production promotion | The approved artifact is deployed consistently. | Copy DAG package, update container image, or deploy through GitOps. |
The key is not to make GitHub Actions run the whole data platform. The key is to stop broken workflow code before it reaches Airflow. A CI pipeline should not need production credentials to validate basic correctness. It should import the DAG, run pure functions, check expected outputs, and verify that the repository contains the operational metadata required by the team.
name: validate-airflow-dags
on:
pull_request:
paths:
- "shared/labs/ch11_orchestration/**"
- ".github/workflows/validate-airflow-dags.yml"
jobs:
test-dags:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- uses: actions/setup-python@v5
with:
python-version: "3.11"
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install pandas pytest
- name: Run orchestration tests
run: pytest -q shared/labs/ch11_orchestration/tests
- name: Run deterministic sample pipeline
run: |
python shared/labs/ch11_orchestration/run_pipeline.py
python shared/labs/ch11_orchestration/validate_outputs.pyThis workflow is intentionally modest. It does not require production credentials. It does not run expensive Spark jobs. It catches common failures early: invalid Python, missing imports, broken dependency definitions, accidental secrets, and incorrect transformation logic. More advanced teams can add container builds, security scans, staging deployments, and synthetic backfills.
11.6 Modern Alternatives: Prefect and Dagster¶
Airflow remains a major standard, but newer orchestrators have introduced different abstractions. Prefect emphasizes Python-native dynamic workflows. Its documentation highlights Pythonic workflows, robust state and recovery, flexible portable execution, event-driven triggering, dynamic runtime behavior, a modern UI, and CI/CD-first development.6 Dagster emphasizes data assets. Its documentation explains that a common way to create a data asset is to annotate a Python function with @dg.asset; the asset definition includes an asset key, upstream asset keys, and a function responsible for computing and storing the asset.7
These tools are not merely “Airflow but newer.” They reflect different mental models. Airflow asks you to think in scheduled tasks. Prefect asks you to start from Python functions and flows. Dagster asks you to model the data products themselves as assets and then reason about how those assets are materialized.
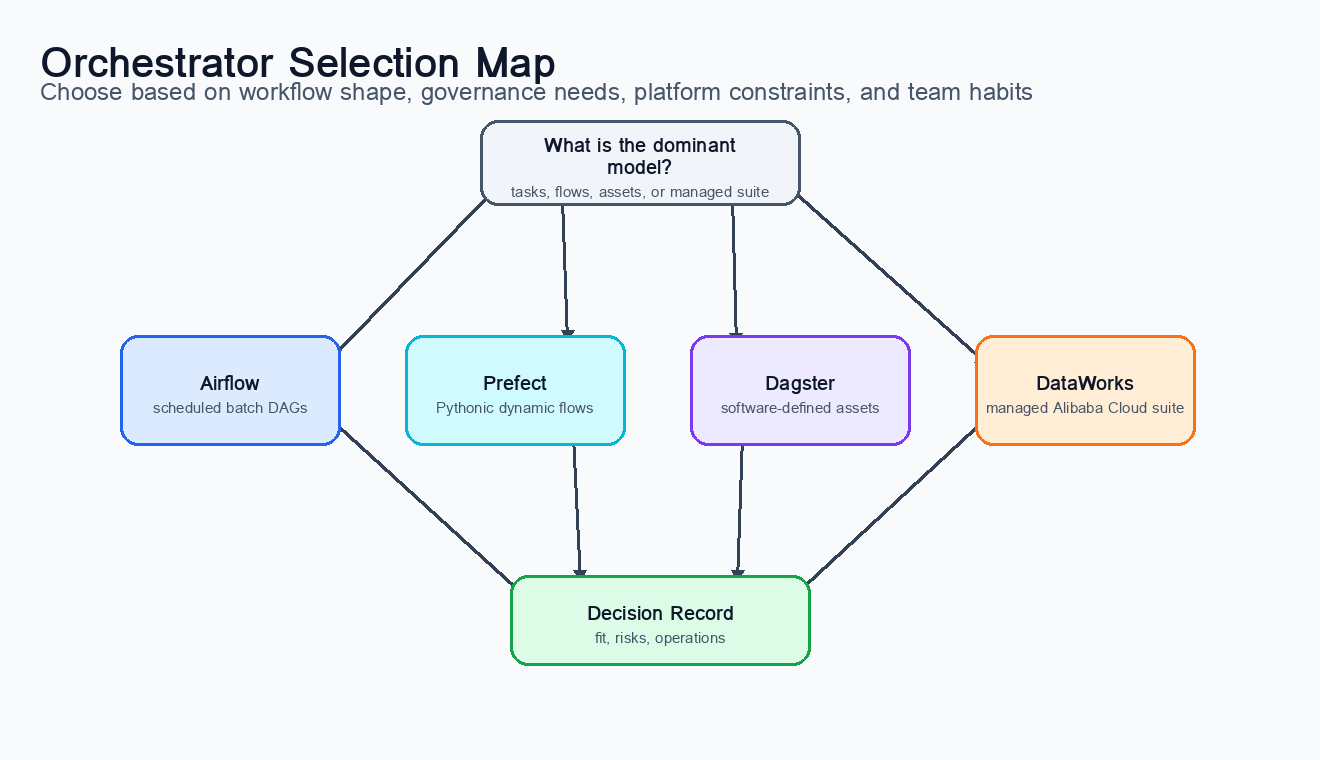
Figure 7:A practical orchestrator selection map. The right choice depends less on popularity and more on platform constraints, team habits, workflow shape, governance needs, and operational capacity.
| Dimension | Apache Airflow | Prefect | Dagster |
|---|---|---|---|
| Primary mental model | Scheduled DAG of tasks. | Python flows and tasks. | Software-defined data assets. |
| Best fit | Recurring finite batch workflows with many integrations and mature operational needs. | Dynamic Python-heavy workflows that need flexible runtime behavior and portable execution. | Teams that want asset lineage, typed assets, and a data-product-centric development model. |
| Development style | Python DAG files and workflows-as-code culture. | Native Python decorators and normal Python control flow. | Python asset definitions and asset dependency graphs. |
| Operational strengths | Backfills, scheduling semantics, large ecosystem, mature UI, broad community. | State recovery, dynamic task creation, event-driven triggering, hybrid deployment patterns. | Asset catalog, lineage, materialization history, asset checks, clear data ownership. |
| Watch-outs | Not ideal for continuously running streaming jobs; scheduler complexity grows with very large DAG fleets.1 | Requires discipline to keep dynamic workflows understandable and testable. | Asset modeling requires a shift in thinking and more upfront design. |
A team choosing an orchestrator should avoid the trap of evaluating only features. The more important question is organizational fit. If the platform team already operates Kubernetes and wants code-first portability, Airflow or Prefect may be natural. If the analytics engineering team thinks in tables, metrics, freshness, and lineage, Dagster may fit the mental model better. If the business mainly needs a reliable daily schedule with rich provider integrations, Airflow may be the pragmatic default.
TuranMart can use this comparison as a decision exercise. The daily sales pipeline is a recurring finite batch workflow with clear dependencies, backfills, and many integration points, so Airflow is a strong fit. A fraud feature workflow that creates dynamic branches for many experimental model segments might be easier in Prefect. A governed warehouse program where every table is a declared product with owners, checks, and lineage might benefit from Dagster’s asset model.
11.7 Managed Cloud Orchestration with Alibaba Cloud DataWorks¶
For organizations building heavily on Alibaba Cloud, DataWorks provides a managed alternative to self-operating an orchestration platform. Alibaba Cloud describes DataWorks as a platform as a service that offers Data Integration, DataStudio, Data Map, Data Quality, and DataService Studio, together with an end-to-end data development and management console.8 In practice, this means the platform combines workflow development, scheduling, data integration, governance, and quality features inside a cloud-native product experience.
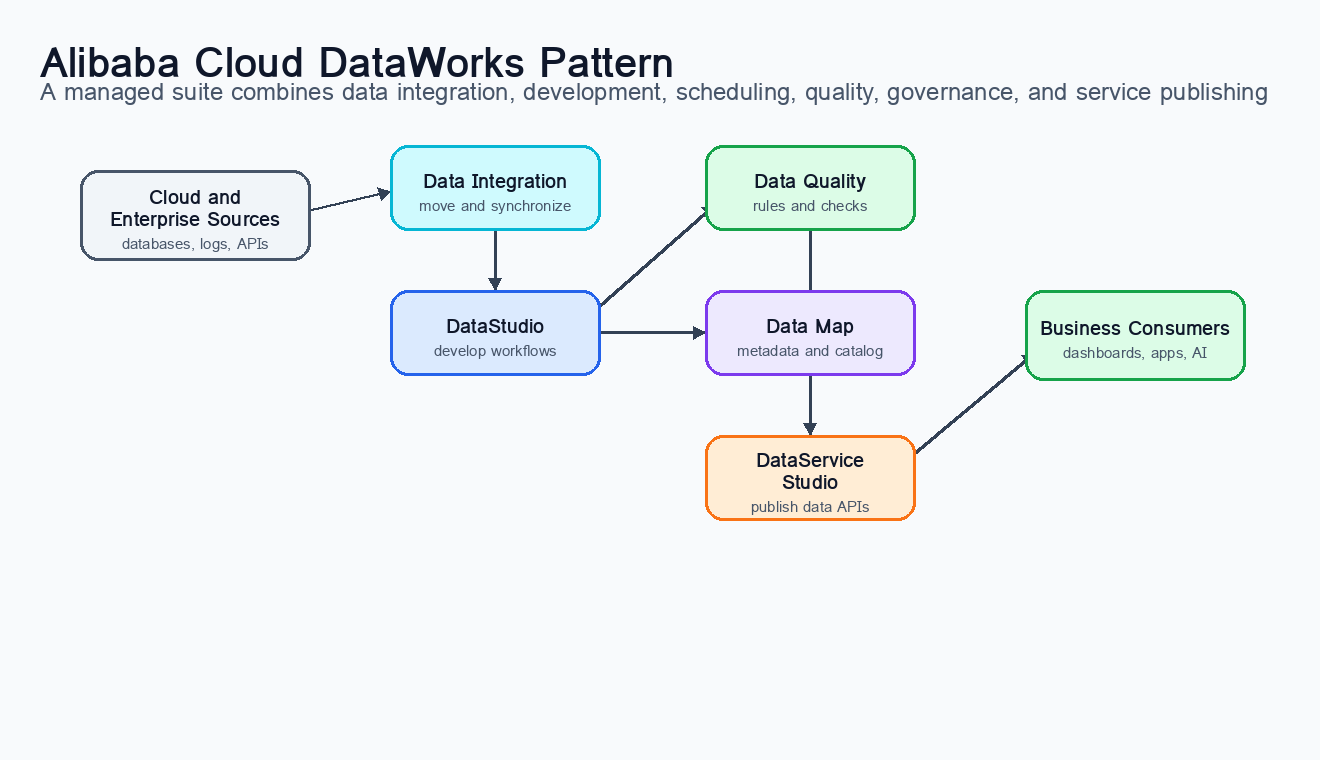
Figure 8:Alibaba Cloud DataWorks provides a managed environment for data integration, development, scheduling, quality, governance, and service publishing in the Alibaba Cloud ecosystem.
DataWorks is attractive when the organization wants integrated cloud services rather than assembling a platform from separate open-source components. A team can connect Alibaba Cloud data sources, develop workflows visually, schedule jobs, inspect metadata, and apply quality and governance controls through one managed interface. This can be especially valuable for teams that need faster onboarding, enterprise governance, and reduced infrastructure maintenance.
However, managed integration has a trade-off. A DataWorks-centered platform may be less portable than a code-first orchestration layer that can run across clouds. If the company expects to use multiple clouds, on-premises systems, or custom execution environments, open-source orchestrators may provide more flexibility. If the company is committed to Alibaba Cloud and wants to minimize platform operations, DataWorks can be a pragmatic choice.
| Use DataWorks when... | Use Airflow, Prefect, or Dagster when... |
|---|---|
| Most critical workloads run on Alibaba Cloud services. | The platform spans several clouds, on-premises systems, or many custom services. |
| The team values a managed console and integrated governance over low-level customization. | The team wants workflows as code, custom Python libraries, and repository-based delivery. |
| Data quality, data cataloging, and data development should be managed in one suite. | The organization already has separate observability, catalog, CI/CD, and execution systems. |
| Platform operations capacity is limited. | The team can operate and upgrade orchestration infrastructure. |
The durable lesson is not that managed tools are better or worse than open-source tools. The lesson is that orchestration architecture must match the operating model. If TuranMart has a small platform team and a strong Alibaba Cloud commitment, DataWorks can reduce operational burden. If TuranMart wants a portable code-first platform across local development, open-source tooling, and multiple clouds, Airflow remains easier to fit into a repository-centered engineering workflow.
11.8 Design Pattern: DAGs as Deployable Data Products¶
A production DAG should be treated as a deployable data product. This pattern combines the technical DAG file with operational metadata, tests, runbook guidance, and deployment controls. The goal is to make the DAG trustworthy enough that other teams can depend on it without needing to ask the original author every morning.
| Data product field | TuranMart example | Why it matters |
|---|---|---|
| Product name | gold.daily_sales | Gives the pipeline an owned business identity. |
| DAG ID | turanmart_daily_sales | Links product behavior to orchestration history. |
| Owner | data-platform for orchestration; analytics for business rules | Makes escalation unambiguous. |
| Schedule | Daily at 06:00 platform time | Sets expectations for automated execution. |
| Data interval | One order date partition | Prevents accidental whole-table processing. |
| Inputs | raw/orders/dt={{ ds }} and product dimension snapshot | Defines upstream dependencies and contracts. |
| Outputs | Bronze partition, gold daily sales CSV or table, quality report | Defines what downstream users can rely on. |
| Freshness target | Available by 07:30 | Turns “on time” into a measurable objective. |
| Tests | DAG import, unit tests, expected-output comparison, contract scan | Prevents broken changes from reaching production. |
| Rollback | Revert DAG package and preserve previous output partition | Supports controlled recovery after bad deployment. |
This pattern prevents a common failure mode: the DAG exists, but no one knows whether it is a critical product, an experimental job, or an old script that happens to run every night. The operational wrapper makes the DAG reviewable. A pull request can ask not only “Does the code run?” but also “Is the schedule correct? Are outputs idempotent? Are owners present? Does the freshness target match the dashboard deadline? Are alerts actionable?”
A deployable DAG product also separates concerns. The DAG file should express orchestration. Transformation functions should be testable outside Airflow. Configuration should be environment-aware. Secrets should live in secret managers or Airflow connections, not in the repository. Expected outputs should be small enough for CI but representative enough to catch broken logic. Runbooks should explain what to do when a task fails, when a backfill is required, and when a downstream consumer must be notified.
For Part III of this book, Chapter 11 acts as the capstone for processing and orchestration. Chapters 8, 9, and 10 taught batch processing, streaming, transformations, testing, and analytics engineering. This chapter connects those skills into a production delivery loop. A pipeline is not complete when the transformation script works once; it is complete when it is scheduled, tested, observable, recoverable, and safely deployable.
11.9 Guided Lab: Build a Production-Style TuranMart Orchestration Project¶
In this lab, you will create a small but realistic orchestration project for TuranMart’s daily sales pipeline. The purpose is not to master every Airflow operator. The purpose is to practice the engineering habits that make orchestration reliable: partitioned processing, idempotent outputs, explicit checks, tests, expected-output validation, and CI/CD readiness.
The lab assets are stored in shared/labs/ch11_orchestration/. The project uses plain Python functions and an Airflow-compatible DAG structure so that readers can run the deterministic pipeline locally without installing a full Airflow server. The tests validate both the transformation logic and the metadata contract expected from a production DAG.
| Artifact | Location | Purpose |
|---|---|---|
| DAG file | shared/labs/ch11_orchestration/dags/turanmart_daily_sales.py | Defines schedule, tasks, retries, dependencies, and operational metadata. |
| Transformation module | shared/labs/ch11_orchestration/src/turanmart_orchestration/transforms.py | Keeps business logic testable outside the Airflow runtime. |
| Sample data | shared/labs/ch11_orchestration/data/raw/orders.csv | Provides deterministic TuranMart order data. |
| Pipeline runner | shared/labs/ch11_orchestration/run_pipeline.py | Executes the lab pipeline locally and writes partitioned outputs. |
| Validator | shared/labs/ch11_orchestration/validate_outputs.py | Compares actual outputs with expected outputs and checks quality metadata. |
| Tests | shared/labs/ch11_orchestration/tests/ | Validates DAG metadata, dependency order, idempotent transforms, and expected failure behavior. |
| CI workflow | shared/labs/ch11_orchestration/.github/workflows/validate-airflow-dags.yml | Shows a repository workflow that would validate the DAG before deployment. |
| Solution guide | shared/solutions/ch11_orchestration/solution_guide.md | Explains the reference output and extension ideas. |
Step 1: Write the DAG Contract¶
Before writing code, write the contract. A DAG contract prevents the team from hiding business assumptions inside task code. In the lab, the contract is stored as dag_contract.yml so tests and documentation can inspect it.
| Contract field | Example value |
|---|---|
| DAG ID | turanmart_daily_sales |
| Owner | data-platform |
| Schedule | Daily at 06:00 local platform time |
| Data interval | One calendar day of orders |
| Inputs | Daily orders.csv partition from the raw landing zone |
| Outputs | Bronze orders partition, gold daily sales summary, quality report |
| Freshness target | Gold summary available by 07:30 |
| Retry policy | Two retries with exponential backoff for transient tasks |
| Alert rule | Alert after final failure or freshness miss |
The contract should be stored near the DAG as documentation. In production, the same information can feed a data catalog, an on-call runbook, and a service-level objective dashboard.
Step 2: Keep Business Logic Outside the DAG File¶
The transformation logic should be testable without starting Airflow. Keep pure functions in a separate module. A build_daily_sales function can accept a dataframe and return a deterministic summary. The Airflow task then becomes a thin wrapper that loads input, calls the function, and writes output for the target partition.
def build_daily_sales(orders: pd.DataFrame) -> pd.DataFrame:
required = {"order_id", "order_date", "region", "order_total"}
missing = required.difference(orders.columns)
if missing:
raise ValueError(f"Missing required columns: {sorted(missing)}")
return (
orders.groupby(["order_date", "region"], as_index=False)
.agg(order_count=("order_id", "nunique"), revenue=("order_total", "sum"))
.sort_values(["order_date", "region"])
)This separation is not only cleaner. It is faster. Unit tests can run in seconds without a scheduler, database, or webserver. CI can catch most business-logic errors before the DAG is deployed.
Step 3: Write Idempotent Partition Outputs¶
The lab writes outputs under output/bronze/orders/dt=..., output/gold/daily_sales/dt=..., and output/quality/dt=.... The writer uses a temporary file and then replaces the final path. This small habit prevents downstream readers from seeing a half-written output. The same idea appears at larger scale in table formats, warehouse transactions, and object-storage commit protocols.
def write_partition(df: pd.DataFrame, output_dir: Path, partition: str, name: str) -> Path:
final_path = output_dir / f"dt={partition}" / name
temp_path = output_dir / f"dt={partition}" / f"{name}.tmp"
final_path.parent.mkdir(parents=True, exist_ok=True)
df.to_csv(temp_path, index=False)
temp_path.replace(final_path)
return final_pathRun the pipeline twice. The second run should produce the same files with the same content. If a retry creates duplicate rows, the validation script should fail.
Step 4: Define the DAG Metadata and Dependencies¶
The lab DAG file is intentionally Airflow-compatible in structure but lightweight enough to inspect without requiring a live Airflow installation. In a production repository, the same ideas would be implemented with Airflow’s @dag and @task decorators or classic operators.
DAG_SPEC = {
"dag_id": "turanmart_daily_sales",
"description": "Build daily TuranMart sales metrics from raw orders.",
"schedule": "0 6 * * *",
"owner": "data-platform",
"retries": 2,
"retry_delay_minutes": 5,
"catchup": True,
"max_active_runs": 1,
"tags": ["turanmart", "sales", "gold"],
}
TASKS = [
{"task_id": "check_source_available", "upstream": []},
{"task_id": "ingest_orders_bronze", "upstream": ["check_source_available"]},
{"task_id": "validate_bronze_orders", "upstream": ["ingest_orders_bronze"]},
{"task_id": "build_daily_sales_gold", "upstream": ["validate_bronze_orders"]},
{"task_id": "write_quality_report", "upstream": ["build_daily_sales_gold"]},
]This file gives tests something concrete to validate. The tests can reject missing owners, empty descriptions, duplicate task IDs, cycles, and unsafe dependency order before the pipeline ever reaches production.
Step 5: Add Import, Contract, and Transformation Tests¶
The fastest useful orchestration test is an import test. It catches syntax errors, missing modules, and broken top-level imports before a DAG reaches the scheduler. The lab also includes tests for pure transformation functions and DAG contract metadata.
def test_dag_has_required_metadata():
assert dag.DAG_SPEC["dag_id"] == "turanmart_daily_sales"
assert dag.DAG_SPEC["owner"] == "data-platform"
assert dag.DAG_SPEC["description"]
assert "gold" in dag.DAG_SPEC["tags"]
def test_build_daily_sales_aggregates_by_date_and_region():
result = build_daily_sales(sample_orders)
assert result.loc[0, "revenue"] == 170.50If the test suite fails, the pull request should not be merged. That rule matters more than the specific testing framework.
Step 6: Validate Expected Outputs and Practice Backfill Thinking¶
The lab includes an expected daily sales output for two partitions. After running run_pipeline.py, execute validate_outputs.py. The validator compares actual output against expected CSV files and checks the quality report status. This simulates the smallest useful CI quality gate for a data pipeline.
cd shared/labs/ch11_orchestration
python run_pipeline.py
python validate_outputs.py
pytest -q testsFinally, practice a backfill scenario. Imagine that TuranMart finds an incorrect discount rule for one day. In this local lab, you rerun the deterministic runner for the affected partition and prove that the output is replaced, not duplicated. In production Airflow, the same principle would be applied through a controlled backfill command and a recorded change reason.
11.10 Common Pitfalls and How to Avoid Them¶
The most common orchestration failure is hidden non-idempotency. A task succeeds during normal daily runs but corrupts data during retry because it appends rows instead of replacing the intended partition. The fix is to design output writes before designing the schedule. Every task should have a clear answer to the question: “If this task runs twice for the same data interval, what exactly changes?”
Another frequent pitfall is putting too much business logic inside DAG files. DAG files should be easy for the scheduler to parse. Heavy imports, network calls at parse time, and large computations at module import time can slow down or destabilize the scheduler. Keep business logic in modules and call it from tasks. Keep DAG files focused on orchestration structure.
A third pitfall is treating retries as a substitute for correctness. Retries help with temporary failures such as network timeouts, rate limits, or brief database unavailability. Retries do not fix bad code, invalid data, or a broken upstream contract. If a data quality check fails because required columns are missing, retrying repeatedly only delays the alert.
| Pitfall | Symptom | Better approach |
|---|---|---|
| Non-idempotent writes | Retries create duplicate rows or inconsistent partitions. | Use deterministic partition overwrite, temporary paths, transactions, or merge keys. |
| Heavy DAG parsing | Scheduler becomes slow or unstable. | Avoid top-level network calls and heavy computation in DAG files. |
| Overly large tasks | Failures require rerunning too much work. | Split by meaningful boundaries: ingest, validate, transform, publish. |
| Too many tiny tasks | UI becomes noisy and scheduler overhead grows. | Combine steps that always fail and recover together. |
| Secrets in code | Credentials leak through Git history or logs. | Use Airflow connections, secret managers, and environment-specific configuration. |
| Alert fatigue | Teams ignore noisy notifications. | Alert only on actionable final failures, freshness misses, or contract violations. |
| Untested DAG imports | Scheduler discovers broken Python after deployment. | Import DAGs in CI and fail the pull request before merge. |
| Backfill without communication | Historical metrics change without business context. | Announce the backfill, limit concurrency, monitor outputs, and record the reason. |
The healthiest teams review orchestration incidents as design feedback. A failed task is not only an interruption; it is evidence. If the same sensor times out every Monday, the schedule may be wrong. If a validation task catches missing columns every week, the upstream contract needs attention. If a backfill takes longer than the original incident, the data layout may not support partition repair well enough.
11.11 Exercises¶
Extend the TuranMart DAG contract with a second output called
gold.region_inventory_risk. Define its schedule, owner, upstream dependencies, quality checks, freshness target, and alert rule.Write a unit test for
build_daily_salesthat verifies revenue is aggregated correctly byorder_dateandregion. Add a second test that verifies the function raises an error whenorder_totalis missing.Design a retry policy for three different task types: an API extraction task, a deterministic SQL transformation, and a notification task that posts to a chat channel. Explain why the policies should differ.
Create a small decision memo comparing Airflow and Dagster for a team that wants stronger lineage around warehouse tables. Your memo should include at least three trade-offs, not only a final recommendation.
Add a CI/CD quality gate that rejects any DAG without an
owner,tags, and a non-emptydescription. Explain whether this rule should be enforced by a linter, a unit test, or code review.Simulate a backfill for one partition in the lab. Run the pipeline twice for the same date, compare the outputs, and explain why the result is or is not idempotent.
Update the sample GitHub Actions workflow so it also uploads the lab quality report as a workflow artifact. Explain what information should and should not be included in artifacts.
Write a short runbook entry for a failure in
validate_bronze_orders. Include the first three checks an on-call engineer should perform and the conditions under which the pipeline can be rerun.
11.12 Review Questions¶
Why is orchestration different from simple time-based scheduling?
What does it mean for a task to be idempotent, and why is idempotency essential for retries and backfills?
What is the difference between a DAG, a DAG run, a task, and a task instance?
Why should heavy computations and network calls be avoided at DAG parse time?
When should a failure be retried automatically, and when should it fail fast?
What operational risks can a backfill create, even when the code is correct?
What kinds of tests should run in CI before a DAG is deployed to production?
How do Airflow, Prefect, and Dagster differ in their primary mental models?
When might Alibaba Cloud DataWorks be preferable to a self-managed Airflow deployment?
What information should be included in a DAG contract for a business-critical data product?
Chapter Summary¶
Orchestration is the control plane that turns individual data jobs into reliable data products. It records dependencies, schedules, task states, retries, backfills, and operational history. Apache Airflow remains a central open-source tool because it combines Python-based workflows as code with scheduling, monitoring, rich integrations, and backfill semantics.1 GitHub Actions complements Airflow by validating and delivering DAG code through repository-centered CI/CD workflows.2
The larger lesson is that orchestration is not only a tool choice. It is an engineering discipline. Good pipelines are idempotent, partition-aware, observable, tested, and deployed through controlled change management. Airflow, Prefect, Dagster, and DataWorks each support this discipline through different abstractions: tasks, flows, assets, or managed cloud development. The best choice depends on workflow shape, team skills, platform strategy, governance needs, and operational capacity.
This chapter closes Part III of the book. You now have the core production pipeline loop: storage systems hold data, processing engines transform it, tests validate it, and orchestration coordinates it. In the next part, we move from building pipelines to operating them responsibly through observability, reliability, governance, security, and cloud architecture.