At 09:04 on a Friday morning, TuranMart’s growth team sees a campaign spike from Tashkent, Almaty, and Bishkek. The batch dashboard from Chapter 8 will show the final result tomorrow, but the operations team needs to know now whether customers are browsing successfully, whether checkout is slowing down, and whether payment failures are concentrated in one region. The fraud team has a similar problem. A suspicious transaction that is detected six hours later is an accounting problem; the same transaction detected in seconds can still be blocked.
This is the moment when data engineering becomes continuous. The platform must capture business events as they happen, preserve them in a replayable log, process them with time-aware logic, publish operational metrics, and still keep the raw history available for later reconciliation. In this chapter, we design that system with Apache Kafka as the distributed event backbone and Apache Flink as the stateful stream-processing engine. Kafka provides durable event streams that many consumers can read independently, while Flink turns those streams into event-time windows, alerts, enriched records, and continuously updated outputs.[1] [2]
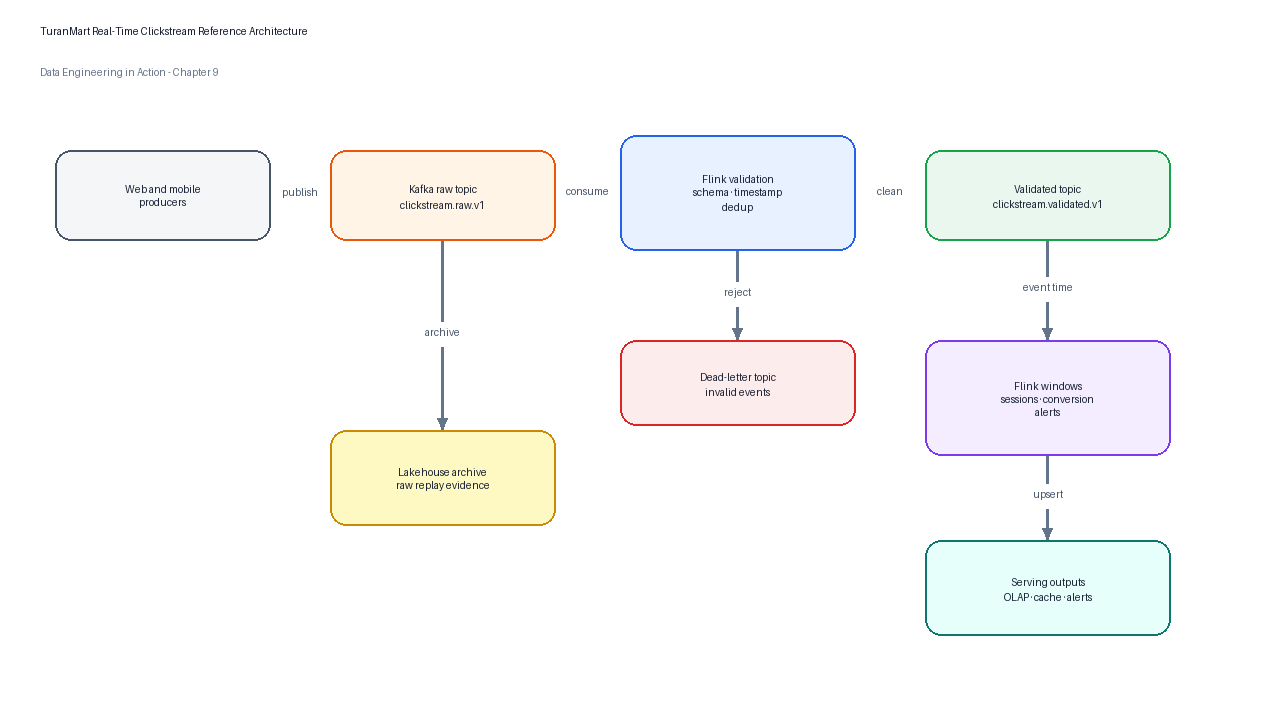
Figure 1:TuranMart’s real-time clickstream architecture separates event capture, Kafka buffering, stateful Flink computation, operational serving, raw archival, and monitoring feedback.
Learning Objectives¶
By the end of this chapter, you should be able to:
Explain why streaming systems process unbounded event streams differently from batch jobs over bounded datasets.
Design Kafka topics, partitions, keys, offsets, and consumer groups for a replayable event backbone.
Apply Flink concepts such as event time, watermarks, windows, state, checkpoints, and late-data handling.
Compare latency, completeness, throughput, replayability, and operational complexity when choosing streaming patterns.
Validate a streaming pipeline with deterministic output keys, idempotent sinks, lag metrics, and failure-recovery checks.
Troubleshoot common production streaming problems such as hot partitions, late events, state growth, and sink backpressure.
9.1 From Batch Thinking to Streaming Thinking¶
Batch processing begins with a bounded input. A job reads yesterday’s orders, transforms them, writes output tables, and stops. Streaming begins with an input that does not naturally end. A clickstream, payment feed, sensor topic, or service log keeps producing records as the business operates. The data engineer therefore has to reason about continuous arrival, partial knowledge, out-of-order records, replay, and long-running operational health.
The most important design question is not “How fast can the tool go?” but “When does the business decision lose value?” TuranMart can wait until tomorrow to recompute a quarterly customer segment, but it cannot wait until tomorrow to detect a failing checkout gateway during a promotion. Freshness is therefore a business requirement before it is a technical requirement.
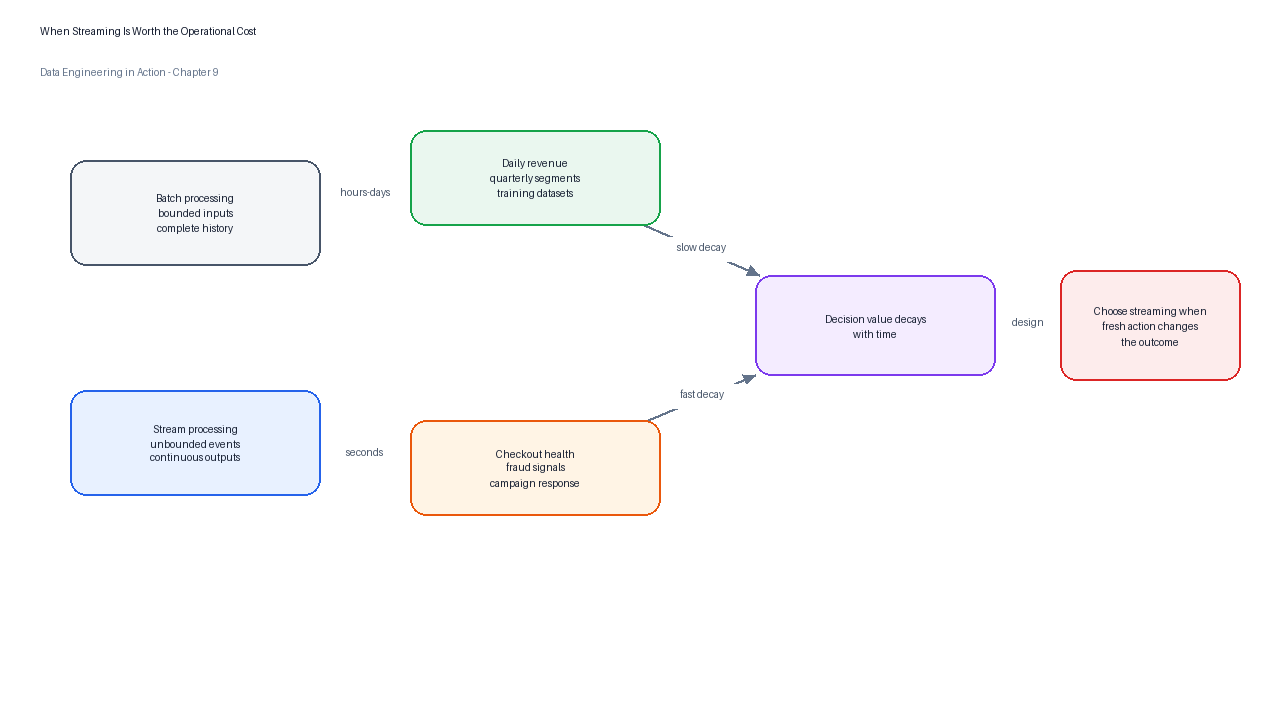
Figure 2:Streaming is justified when the value of action decays faster than a batch pipeline can deliver a trustworthy result.
| Dimension | Batch processing | Stream processing | Engineering implication |
|---|---|---|---|
| Input shape | Bounded files, tables, or partitions | Unbounded append-only events | Streaming jobs require lifecycle management because they do not naturally finish. |
| Time model | Usually scheduled processing time | Event time and processing time both matter | Metrics need explicit timestamp, watermark, and late-data rules. |
| Recovery model | Re-run from durable input | Resume from source offsets and restored state | Sources must be replayable and sinks must tolerate retries. |
| Correctness risk | Missing files, partial partitions, bad joins | Duplicates, late events, reordering, state loss | Idempotency, deduplication, and state checkpoints become design concerns. |
| Cost profile | Compute is concentrated during runs | Compute and state are continuously active | Capacity, lag, and backpressure must be monitored continuously. |
| Best use cases | Historical marts, backfills, training datasets | Alerts, live dashboards, fraud signals, IoT monitoring | Use streaming only when freshness changes the outcome. |
Streaming is not faster batch. It is a different operating model in which the system produces useful results while the input is still arriving and while the final historical truth may still be incomplete.
Key Concepts¶
The vocabulary of streaming systems is small, but each term carries operational consequences. A team that uses the word “real time” without defining event time, lateness, replay, and sink behavior is not yet ready to operate a production stream.
| Concept | Definition | Why it matters |
|---|---|---|
| Event | Immutable record that something happened at a point in time | Events are the contracts shared by producers, stream processors, and consumers. |
| Topic | Named Kafka stream of records | Topics organize ownership, retention, schema, access control, and replay. |
| Partition | Ordered shard of a Kafka topic | Partitions provide parallelism, but ordering is guaranteed only within a partition. |
| Offset | Position of a record inside a partition | Offsets make replay and recovery possible, but they are not business identifiers. |
| Consumer group | Set of consumers that cooperatively read topic partitions | Consumer groups allow independent applications to read the same stream without blocking each other. |
| Event time | Time at which the event occurred in the business system | Event time is required for trustworthy windows when records arrive late or out of order. |
| Watermark | Processor’s estimate of progress in event time | Watermarks decide when windows can emit and how late events are handled. |
| State | Data remembered by a streaming operator across events | State enables joins, windows, sessions, and pattern detection, but must be checkpointed and cleaned up. |
| Checkpoint | Durable snapshot of source positions and operator state | Checkpoints allow recovery after failures without starting the job from zero. |
| Idempotent sink | Output system that can receive the same logical result more than once without changing correctness | Idempotent writes are essential when retries or replays occur. |
Designing Events as Contracts¶
An event should describe a fact in the business domain, not merely expose an internal database row. A good TuranMart checkout_started event includes an event identifier, customer or anonymous session key, event time, region, device type, schema version, and relevant checkout metadata. A good payment_authorized event includes the transaction identifier, order identifier, amount, currency, authorization time, payment method class, and risk metadata.
| Event field | Example | Design purpose |
|---|---|---|
event_id | evt_20260101_000042 | Deduplication, traceability, and replay audit. |
event_type | add_to_cart | Clear business meaning for consumers. |
event_time | 2026-01-01T09:04:17Z | Event-time windows and late-data handling. |
entity_key | session_id=s_1042 | Partitioning and per-entity ordering. |
schema_version | v3 | Explicit evolution and compatibility checks. |
producer | web-checkout-service | Ownership, debugging, and incident response. |
trace_id | trc_8e6b... | Cross-service observability. |
Events are usually immutable. If an order changes state, the producer emits a new fact such as order_cancelled or payment_refunded. This append-only design makes streams replayable and lets multiple downstream teams build independent products from the same history.
9.2 Kafka as the Event Backbone¶
Apache Kafka describes itself as an open-source distributed event streaming platform for data pipelines, streaming analytics, data integration, and mission-critical applications.[1] Its documentation lists use cases such as messaging, website activity tracking, metrics, log aggregation, stream processing, event sourcing, and commit-log replication.[3] For a data engineer, the essential idea is that Kafka is a durable, partitioned, append-only log that decouples producers from consumers.
A producer writes records to a topic. Kafka stores those records in partitions. Consumers read records at their own pace. Multiple applications can consume the same topic independently, and consumers can replay older records if the topic retention policy still preserves them. This replayable log is the reason Kafka is more than a queue. A queue usually transfers work from one producer to one worker pool. A Kafka topic can become a shared data product.
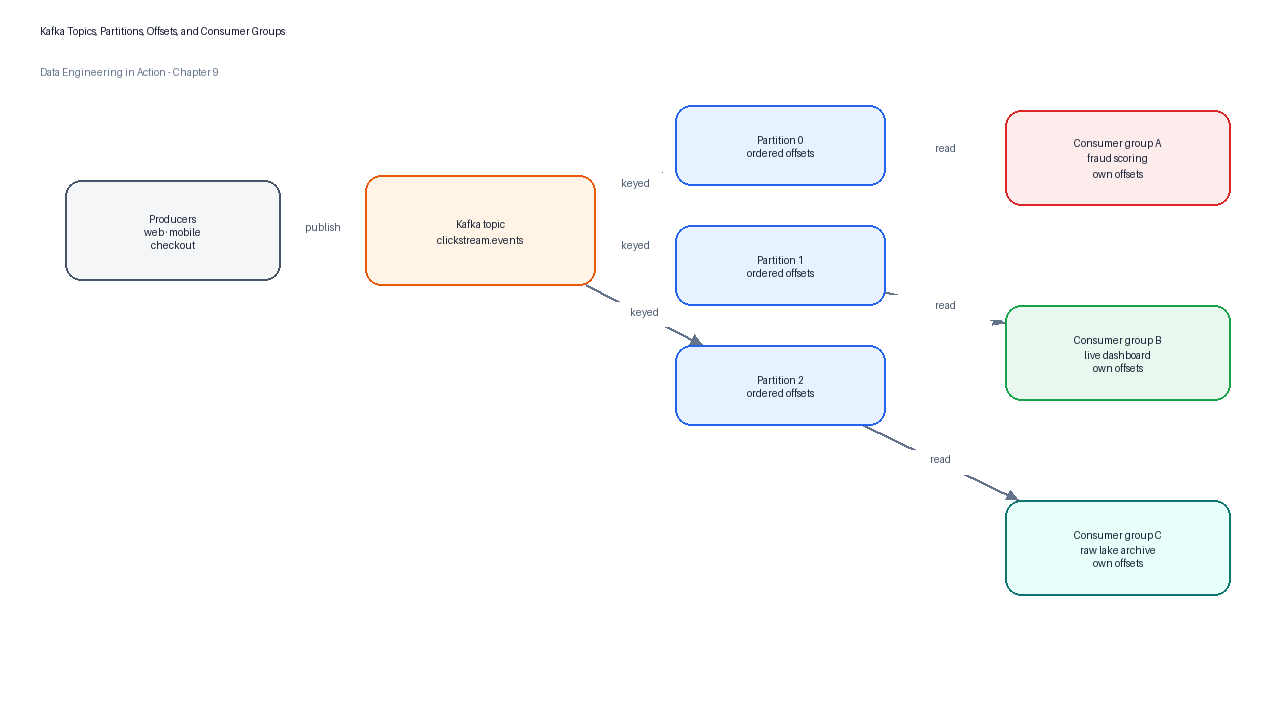
Figure 3:Kafka partitions provide ordering and parallelism; consumer groups let independent applications consume the same topic with their own offsets.
Topics, Partitions, Keys, and Offsets¶
A topic is a named stream such as clickstream.events, orders.lifecycle, or payments.authorizations. A topic is split into partitions, and each partition is an ordered log. Records inside one partition have monotonically increasing offsets. Ordering is guaranteed within a single partition, not across the entire topic.
The partition key is one of the most consequential streaming decisions. If all events for a session must be processed in order, session_id is a natural key. If all payment events for an order must be correlated, order_id may be better. If one key receives much more traffic than others, that choice can create a hot partition that limits throughput.
| Partition-key choice | Good when | Risk | Production signal |
|---|---|---|---|
session_id | Clickstream sessions need ordered behavior | Long or very active sessions can become skewed | Partition-level lag and records per second. |
customer_id | Customer history and personalization need ordering | High-value customers can dominate a partition | Lag by customer segment and hot-key reports. |
order_id | Order, payment, and fulfillment facts must be correlated | Cross-order customer analysis needs repartitioning | Repartition traffic inside Flink. |
region | Operations are regionally isolated | Large regions create uneven load | Broker disk usage and lag by region. |
| Random or event ID | Maximum distribution matters more than ordering | Related events scatter across partitions | Increased join/state complexity downstream. |
Offsets are positions, not facts. Reprocessing from an older offset can regenerate outputs, but it does not automatically make replay safe. Safe replay also requires deterministic transformation logic, compatible schemas, idempotent or transactional sinks, and a plan for side effects such as alerts.
Producers and Delivery Semantics¶
Producer design starts before code. The team should define the topic name, event schema, partition key, timestamp source, serialization format, compression policy, retry behavior, ownership, and expected traffic. A producer that publishes ambiguous events creates downstream confusion; a producer that publishes stable domain facts creates platform leverage.
Streaming delivery semantics are often summarized as at-most-once, at-least-once, and exactly-once. These phrases are useful only when they include the whole path from source through state to sink. Flink documentation is explicit that end-to-end exactly-once behavior requires replayable sources and transactional or idempotent sinks.[4] A pipeline can recover source offsets and operator state correctly but still duplicate business effects if the sink appends non-idempotent rows during retry.
| Semantic goal | Practical meaning | Implementation pattern | Main risk |
|---|---|---|---|
| At-most-once | An event may be lost, but it is not duplicated | Commit progress before processing | Data loss during crashes. |
| At-least-once | Events are not intentionally lost, but effects may repeat | Process first, commit after processing | Duplicate output rows or alerts. |
| Effectively-once | Business result changes once even if processing retries | Deterministic output keys and upserts | Requires careful sink contracts. |
| Exactly-once end to end | Source, state, and sink coordinate one logical effect | Replayable source plus checkpointed state plus transactional or idempotent sink | More complexity and stricter compatibility. |
For most analytics and operations pipelines, effectively-once is the practical target. A windowed metrics table can use a deterministic key such as (metric_name, window_start, window_end, region, device_type) and upsert the latest result. If a retry writes the same logical window again, the table remains correct.
Consumer Groups and Replay¶
Kafka consumers pull records from brokers by specifying offsets, giving consumers control over what they read and allowing them to reconsume data when needed.[5] A consumer group is a set of consumers from the same application that work together. Each partition is consumed by exactly one consumer within a group at a given time, while different groups can read the same topic independently.[5]
This model enables fan-out. TuranMart’s fraud scoring service, operational dashboard job, search-indexing service, raw lake writer, and experimentation platform can all read the same clickstream topic without blocking one another. Each application owns its group ID and offsets.
| Consumer-group concept | Practical meaning | Engineering concern |
|---|---|---|
| Group ID | Logical application identity | Changing it can trigger full replay or a new starting position. |
| Partition assignment | Which consumer reads which partitions | Rebalances can pause consumption and increase lag. |
| Offset commit | Next record the group intends to read | Commit only after processing is safe enough for the semantic target. |
| Lag | Distance between produced records and consumed records | Lag reveals downstream capacity or sink problems. |
| Rebalance | Reassignment after membership or metadata changes | Frequent rebalances indicate unstable consumers or configuration issues. |
Confluent’s Kafka consumer documentation explains that consumer offsets mark the next record to read and are stored in the internal __consumer_offsets topic so consumers can resume after failures or restarts.[5] This small detail is operationally important. If offsets are committed too early, records can be lost. If they are committed too late, records can be reprocessed. The correct strategy depends on the sink’s idempotency and the business tolerance for duplicates or loss.
Governing Kafka as a Data Product¶
A Kafka platform should be governed like shared analytical storage. Topics need owners, schemas, retention policies, data classifications, access controls, and deprecation plans. A one-day retention policy may be enough for short operational recovery. A thirty-day retention policy supports replay and backfills, but it increases storage cost and privacy responsibility. Sensitive topics may require stricter encryption, masking, authorization, and retention limits.
| Governance decision | Example policy | Why it matters |
|---|---|---|
| Ownership | Every topic has a named producing team and consuming data-product owner | Incidents need accountable people, not only infrastructure metrics. |
| Schema compatibility | Backward-compatible additions allowed; breaking changes require a new versioned topic | Consumers should not fail silently when producers deploy. |
| Retention | Raw clickstream retained for 14 days in Kafka and archived to lakehouse for long-term analysis | Kafka supports operational replay; object storage supports historical reconstruction. |
| Access control | Payment topics restricted to fraud and finance-approved consumers | Event logs can contain sensitive operational facts. |
| Deprecation | Topic retirement requires migration window and consumer inventory | Shared streams often outlive the first application that created them. |
9.3 Flink for Stateful Stream Processing¶
Kafka stores and distributes events, but business value usually requires computation. Apache Flink describes itself as a framework and distributed processing engine for stateful computations over unbounded and bounded data streams.[2] Its APIs support transformations, joins, aggregations, windows, state, Table API, and SQL over streaming and batch programs.[6]
Flink becomes important when the computation must remember information across events. A stateless function can parse JSON, filter invalid records, or route events by type. A stateful function can count purchases per customer during the last hour, build clickstream sessions, join orders with payments, detect suspicious patterns, or maintain a rolling feature used by a risk model.
| State pattern | TuranMart example | Main risk | Mitigation |
|---|---|---|---|
| Per-key counter | Purchase attempts per customer in ten minutes | High-cardinality keys increase state size | Use state TTL and aggregate at the correct grain. |
| Session state | Web visits grouped by inactivity gap | Long sessions delay finalization | Tune gap duration and define maximum session length. |
| Stream join | Join checkout_started and payment_authorized | One side arrives late or never arrives | Use time bounds, side outputs, and dead-letter handling. |
| Pattern detection | Three failed payments followed by one high-value retry | Duplicate events trigger false positives | Deduplicate by event ID and use replay-safe outputs. |
| Enrichment cache | Attach product category or campaign metadata | Stale or unbounded dimension state | Use versioned dimensions and explicit expiration. |
A production Flink job should be reviewed like a data model. Engineers should estimate key cardinality, state per key, state time-to-live, expected checkpoint size, rescaling strategy, and the operational impact of late events.
Event Time, Processing Time, and Watermarks¶
Real streams rarely arrive in perfect order. Mobile devices go offline, networks retry, producers buffer, clocks drift, and services recover after outages. If TuranMart calculates conversion by machine arrival time, a purchase that occurred at 09:04 but arrived at 09:07 could be counted in the wrong window. Event-time processing solves this problem by assigning records to business-time windows.
Flink documentation distinguishes processing time, the system time of the machine executing an operation, from event time, the time at which the event occurred on the producing device.[7] It also explains that watermarks are the mechanism for measuring progress in event time: a Watermark(t) declares that event time has reached timestamp t and that no older elements are expected under the configured strategy.[7]
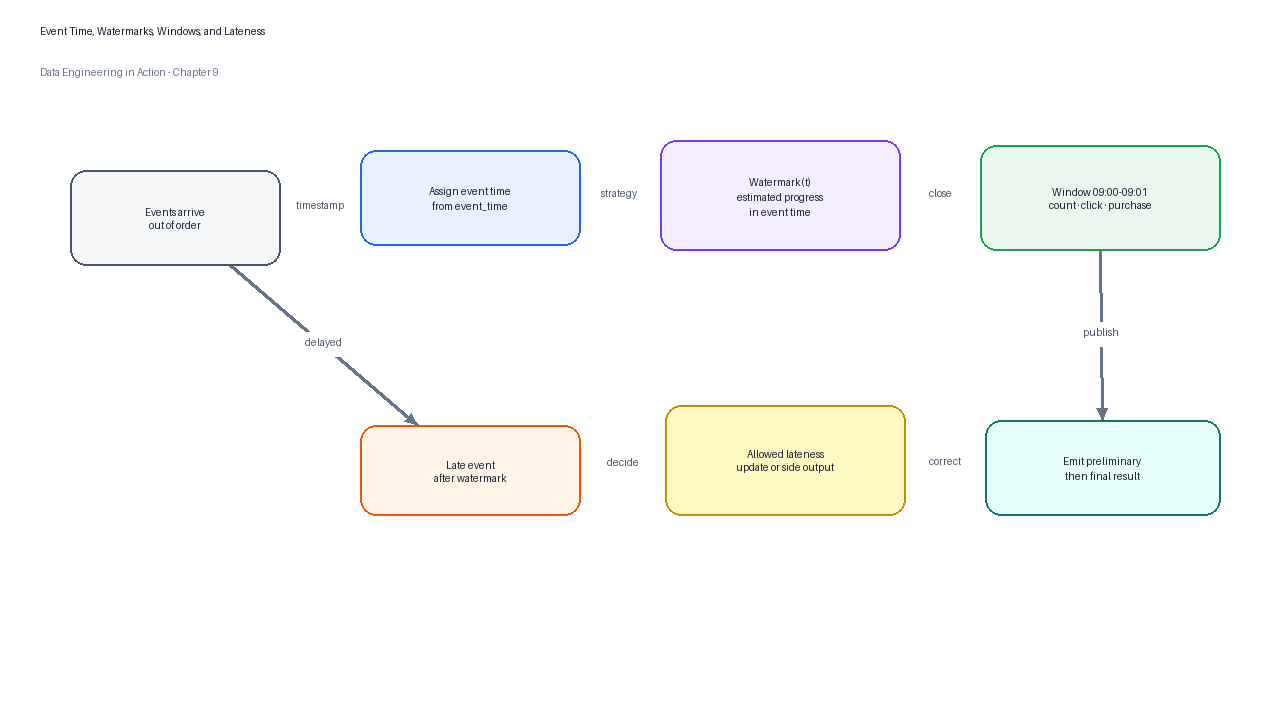
Figure 4:Event-time processing assigns records to business windows, while watermarks determine when the processor believes a window is complete enough to emit.
| Time concept | Meaning | Use | Trade-off |
|---|---|---|---|
| Event time | When the event happened in the source system | Business metrics, sessions, fraud windows | Requires trustworthy timestamps and lateness rules. |
| Processing time | When the stream processor handled the record | Simple low-latency monitoring | Results vary with load, retries, and deployment behavior. |
| Ingestion time | When the event entered the processing system | Compromise when source timestamps are unavailable | Still may not match the real business occurrence time. |
Watermark configuration is a product decision disguised as a runtime parameter. A strict watermark emits quickly but may drop delayed records. A generous watermark improves completeness but increases state retention and delays final results. TuranMart’s live dashboard may label a window as “preliminary” after 20 seconds and “final” after two minutes; the fraud pipeline may choose a stricter threshold because late blocking has less value.
Windowing Patterns¶
Flink’s timely processing documentation explains that aggregates over generally infinite streams must be scoped by windows, and it highlights tumbling, sliding, and session windows as common types.[7] Window selection affects both cost and business meaning.
| Window type | Description | TuranMart use case | Cost and correctness note |
|---|---|---|---|
| Tumbling | Fixed, non-overlapping windows | Conversion rate every minute | Simple and efficient, but boundaries are arbitrary. |
| Sliding | Fixed windows that overlap | Error rate over the last 15 minutes, updated every minute | Smoother trend, more computation and state. |
| Session | Windows separated by inactivity gap | User browsing sessions | Semantically rich but sensitive to gap choice. |
| Global with trigger | One logical unbounded window with custom emissions | Continuous leaderboard or top products | Requires explicit cleanup and careful trigger design. |
A five-minute session gap may split a slow mobile user’s journey into several sessions. A thirty-minute gap may merge unrelated visits and inflate engagement. The correct value is not universal. It depends on user behavior, product design, metric definition, and how the result will be used.
Checkpoints, Savepoints, and Recovery¶
Failures are normal. Machines restart, networks degrade, brokers rebalance, sinks slow down, and deployments roll forward. Flink’s fault-tolerance documentation explains that Flink periodically takes persistent snapshots of operator state and stores them durably so a failed application can restore complete state and resume processing.[4] A snapshot includes pointers into sources, such as Kafka partition offsets, and copies of the state from stateful operators.[4]
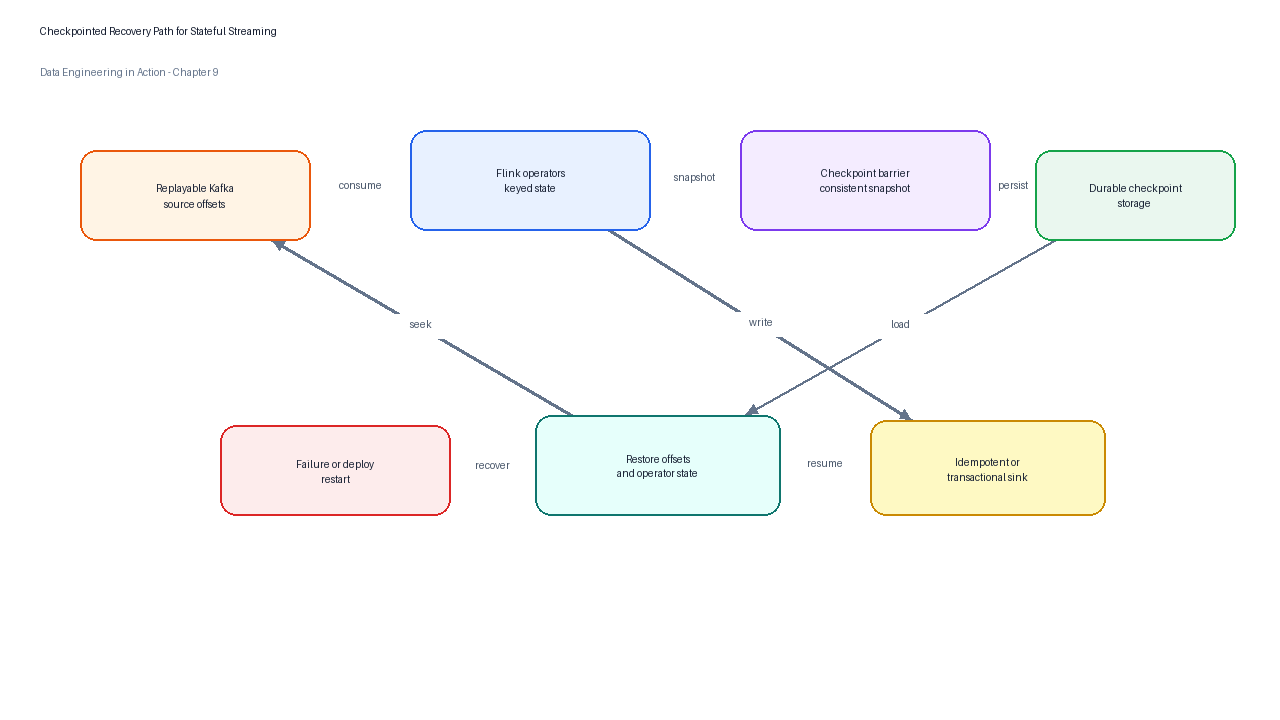
Figure 5:Checkpointed recovery coordinates replayable Kafka offsets, operator state, durable checkpoint storage, and idempotent or transactional sinks.
This model has practical consequences. Source offsets are not enough because the job also needs its operator state. Operator state is not enough because the source must be replayable. Source and state recovery are still not enough if the sink duplicates side effects. Flink documentation states that end-to-end exactly-once behavior requires replayable sources and transactional or idempotent sinks.[4]
| Reliability metric | What it reveals | First response |
|---|---|---|
| Checkpoint duration | Whether state snapshots are becoming slow | Reduce state size, tune backend, or improve checkpoint storage. |
| Checkpoint failures | Whether recovery guarantees are at risk | Investigate backpressure, storage errors, task failures, and timeouts. |
| End-to-end latency | Time from event occurrence to visible output | Tune watermarks, operators, sinks, and capacity. |
| Consumer lag | Whether processing keeps up with Kafka production | Add parallelism, remove bottlenecks, or scale the sink. |
| State size | Whether keyed state is growing beyond expectations | Add TTL, redesign keys, compact state, or split the job. |
9.4 Designing TuranMart’s Real-Time Clickstream Pipeline¶
The reference design in Figure Figure 1 is not “Kafka plus Flink” as a diagramming shortcut. It is a set of engineering commitments. Producers publish governed events. Kafka stores them durably and provides fan-out. Flink validates, timestamps, windows, enriches, and writes results. Serving systems expose low-latency outputs. The lakehouse archives raw and curated data for reconciliation. Monitoring watches freshness, lag, failure, and data-quality signals.
| Output | Consumer | Latency need | Correctness need | Typical sink |
|---|---|---|---|---|
| Fraud signal | Risk engine | Sub-second to seconds | Very high; false positives and false negatives are costly | Key-value store, service API, or alert topic. |
| Live conversion KPI | Growth and operations teams | Seconds | High, with preliminary/final labels | OLAP store, metrics backend, or cache. |
| Raw immutable archive | Data platform | Near-real-time to periodic | Very high completeness and governance | Object storage table format. |
| Enriched event stream | Downstream applications | Seconds | Schema-compatible and replayable | Kafka topic. |
| Incident alert | SRE and business operations | Seconds | High precision with deduplication | Incident platform or notification topic. |
Design Questions Before Implementation¶
Streaming failures often come from unstated assumptions rather than broken syntax. Before building a production job, the team should answer the questions below and store the decisions with the pipeline documentation.
| Design question | Why it matters | Strong answer |
|---|---|---|
| What is the business decision deadline? | “Real time” is otherwise vague | Define freshness SLOs for each output. |
| Which timestamp defines event time? | Window correctness depends on the timestamp | Use producer event time and validate clock skew. |
| What partition key preserves required ordering? | Ordering exists only within partitions | Choose session_id, customer_id, or order_id based on the computation. |
| How much lateness is allowed? | Controls latency-completeness trade-off | Document preliminary and final windows. |
| What state will the job retain? | State controls memory, checkpoint size, and recovery time | Estimate cardinality, TTL, and rescaling behavior. |
| What happens during replay? | Replay can duplicate side effects | Use deterministic output keys and replay isolation. |
| How will schemas evolve? | Producers and consumers deploy independently | Enforce compatibility checks and version ownership. |
| What is the sink contract? | Correctness depends on output behavior | Prefer upserts, transactions, or idempotent writes. |
A Practical Streaming Design Pattern¶
A robust pattern for TuranMart is to separate raw events, validated events, metrics, and alerts. The raw topic preserves original producer output. The validation job writes clean records to a governed topic and rejects malformed records to a dead-letter topic. The metrics job reads clean events, applies event-time windows, and writes deterministic window rows. The alert job reads either clean events or derived features and writes idempotent alert records.
| Layer | Example artifact | Responsibility |
|---|---|---|
| Raw event topic | clickstream.raw.v1 | Preserve producer facts for replay and audit. |
| Validation output | clickstream.validated.v1 | Enforce schema, timestamp, and required-field rules. |
| Dead-letter topic | clickstream.invalid.v1 | Make rejected records visible for producer repair. |
| Windowed metrics | conversion_metrics_1m | Provide operational dashboard facts by window and dimension. |
| Alert stream | checkout_anomaly_alerts.v1 | Publish deduplicated operational alerts. |
| Lakehouse archive | bronze_clickstream and silver_clickstream | Support historical reconciliation and batch recomputation. |
This separation improves operability. If a producer changes schema, the validation layer catches the problem before downstream metrics silently drift. If the metrics definition changes, raw events can be replayed into a new version of the output. If a sink fails, Kafka retains the input long enough for recovery, subject to retention policy.
9.5 Operating Streaming Systems in Production¶
Production streaming systems fail quietly as often as they fail loudly. A batch job that fails usually stops and pages someone. A streaming job can keep running while falling behind, accumulating unbounded state, dropping late events, duplicating alerts, or publishing plausible but wrong metrics. Operations must therefore focus on freshness, completeness, correctness, and recoverability.
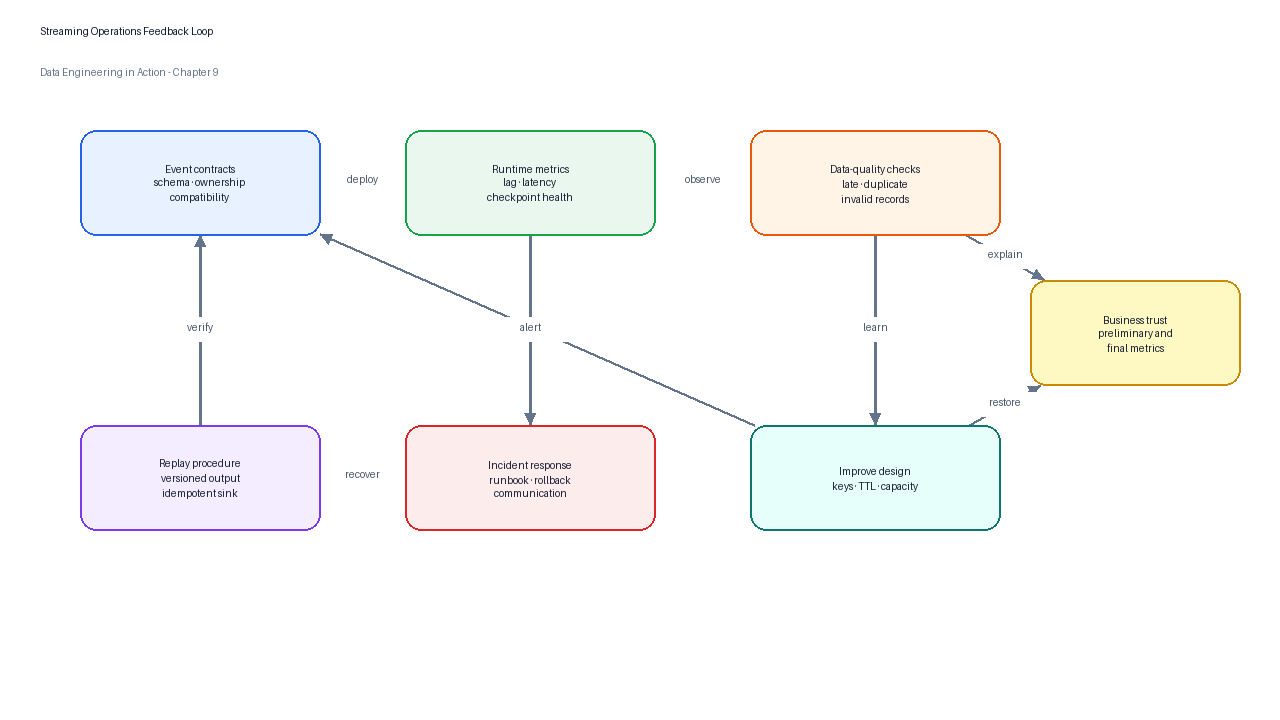
Figure 6:Production streaming operations close the loop between event contracts, runtime metrics, data-quality checks, incident response, and replay procedures.
| Risk | What it looks like | Mitigation | Primary metric |
|---|---|---|---|
| Hot partitions | One partition receives most traffic and its task falls behind | Improve key distribution or add pre-aggregation | Lag and throughput by partition. |
| Unbounded state growth | Checkpoints and memory keep increasing | Add TTL, bound joins, or reduce key cardinality | State bytes and checkpoint duration. |
| Late-event surprises | Dashboards change unexpectedly after publication | Define allowed lateness and finalization labels | Late records per window and correction count. |
| Duplicate outputs | Retries produce repeated rows or alerts | Use deterministic keys, upserts, transactions, or deduplication | Duplicate output rate and sink conflicts. |
| Schema drift | Producers change fields or semantics silently | Use schema registry, compatibility tests, and ownership | Schema validation failures. |
| Sink backpressure | Kafka lag grows because output writes are slow | Scale the sink, batch writes, use async I/O, or buffer with another topic | Backpressure time and sink latency. |
| Rebalance storms | Consumers repeatedly lose partition assignments | Stabilize consumers and tune sessions | Rebalance count and consumer availability. |
Streaming and Batch Together¶
Streaming does not eliminate batch processing. The strongest platforms use both. Streaming powers operational responsiveness; batch powers historical reconciliation, correction, backfills, and training datasets. TuranMart’s live conversion dashboard may update every minute, while the authoritative daily revenue table is rebuilt overnight from the lakehouse with late-arriving records and finance-approved rules.
The two layers should share metric definitions, schema contracts, and identifiers. If the streaming conversion rate and the batch conversion rate differ, the platform should explain why. Perhaps the streaming view is preliminary, or perhaps the batch job applies fraud exclusions that the streaming job does not yet know. Mature data products expose these differences through metadata instead of leaving them as hidden tribal knowledge.
9.6 Guided Lab: Streaming Clickstream Windows¶
The companion lab builds a deterministic event-time window simulator for TuranMart clickstream data. It does not require a full Kafka and Flink cluster, because the first learning goal is conceptual correctness: readers should see how out-of-order events, watermarks, allowed lateness, and deterministic output keys affect a live metric. The same design can later be implemented with Kafka topics and a Flink job.
| Lab material | Location |
|---|---|
| Lab README | README.md |
| Starter simulator | streaming |
| Sample deterministic events | clickstream |
| Expected output | |
| Output validator | validate_outputs.py |
| Exercises | README.md |
| Solution guide | README.md |
Run the standard lab from the repository root:
python3 shared/labs/ch09_streaming_clickstream/streaming_window_simulator.py \
--input shared/labs/ch09_streaming_clickstream/data/clickstream_events.jsonl \
--window-seconds 60 \
--allowed-lateness-seconds 20 \
--output /tmp/ch09_window_metrics.csvThen validate the output:
python3 shared/labs/ch09_streaming_clickstream/validate_outputs.py \
--actual /tmp/ch09_window_metrics.csv \
--expected shared/labs/ch09_streaming_clickstream/expected_output/lateness_20_metrics.csvThe most useful experiment is to run the simulator with allowed lateness set to 0, 20, and 120 seconds, then compare the number of dropped late events, the number of emitted windows, and the stability of conversion-rate estimates. The lesson is not that one lateness value is universally correct. The lesson is that the latency-completeness boundary must match the decision the metric supports.
Expected Output¶
A successful run writes a CSV file with one row per event-time window and deterministic keys. The exact values are generated by the lab assets, but the output has the following shape:
window_start,window_end,dimension,impressions,clicks,purchases,conversion_rate,late_events_dropped,total_events_seen,max_event_lag_seconds
2026-01-01T09:00:00+00:00,2026-01-01T09:01:00+00:00,all,48,11,2,0.04167,0,61,18.35The validator should print a success message when the generated file matches the expected output. If it fails, compare the command arguments first. Different lateness values intentionally produce different reports.
Troubleshooting Notes¶
| Problem | Likely cause | Fix |
|---|---|---|
| Output differs from expected file | The lateness, input path, or window size differs from the standard command | Re-run with --window-seconds 60 and --allowed-lateness-seconds 20. |
| No windows appear | Input file path is wrong or empty | Confirm that data/clickstream_events.jsonl exists and contains JSON lines. |
| Many events are dropped as late | Allowed lateness is too strict for the simulated delay distribution | Increase --allowed-lateness-seconds and explain the latency trade-off. |
| Conversion rate looks unstable | A short window has few impressions | Compare one-minute and five-minute windows. |
| Validator cannot find files | Command is not executed from the repository root | Change into the repository root before running lab commands. |
Common Pitfalls and Design Heuristics¶
Many streaming problems are avoidable when teams slow down before deploying. A clear event contract, deterministic key, documented lateness policy, and idempotent sink prevent more incidents than clever tuning after production traffic arrives.
| Pitfall | Why it hurts | Better habit |
|---|---|---|
| Treating Kafka topics as temporary queues | Consumers lose replay and governance expectations | Treat important topics as versioned data products. |
| Partitioning by a convenient field instead of an ordering requirement | Related events arrive at different operators | Choose keys from business correlation needs. |
| Using processing time for business metrics | Results change with load and retries | Use event time when metric meaning depends on occurrence time. |
| Ignoring sink semantics | Retries duplicate rows, alerts, or external actions | Design deterministic output keys and upserts. |
| Keeping state forever | Recovery becomes slow and checkpoints grow | Define state TTL and bounded joins. |
| Hiding preliminary results | Stakeholders misinterpret changing dashboards | Label windows as preliminary, corrected, or final. |
Exercises¶
Easy Exercise¶
Run the lab with --allowed-lateness-seconds 0 and --allowed-lateness-seconds 20. Compare the total number of dropped late events and explain which output is more complete.
Medium Exercise¶
Change the simulator to compute metrics by region as well as the global all dimension. Explain how this changes output keys, state cardinality, and dashboard interpretation.
Challenge Exercise¶
Design a Kafka and Flink production version of the lab. Specify the raw topic, validated topic, dead-letter topic, partition key, watermark strategy, checkpoint storage, sink type, and monitoring dashboard. Explain how your design handles replay without duplicating output rows.
Team Exercise¶
Assign four roles: producer owner, stream-processing engineer, dashboard owner, and SRE. Conduct a design review for a live checkout conversion metric. Each role must identify one failure mode, one metric, and one runbook action.
Review Questions¶
Why is streaming best understood as a different operating model rather than simply faster batch processing?
What does Kafka guarantee about ordering, and how does that affect partition-key design?
Why are offsets not sufficient by themselves to guarantee correct replay?
How do event time and processing time differ, and why does the difference matter for TuranMart’s dashboard?
What does a watermark represent, and what trade-off does allowed lateness introduce?
Why does a stateful Flink job need checkpoints?
What must be true for end-to-end exactly-once behavior to hold across source, processor, and sink?
Which operational metrics would you put on the first dashboard for a new streaming pipeline?
Chapter Summary¶
This chapter introduced streaming data engineering as the discipline of turning continuous events into timely, trustworthy decisions. We began with TuranMart’s real-time clickstream and fraud needs, then separated batch and streaming thinking. We studied Kafka as a durable, partitioned event backbone with topics, partitions, offsets, keys, producers, and consumer groups. We then studied Flink as a stateful stream-processing engine that uses event time, watermarks, windows, state, and checkpoints to produce correct results over unbounded input.
The central lesson is that streaming correctness is not measured only by low latency. A fast metric that drops important late events, double-counts retries, or hides preliminary status can harm the business. A good streaming design defines event contracts, partitioning, lateness, state retention, checkpointing, sink semantics, replay procedures, and monitoring before production traffic arrives.
In the next chapter, we move from moving and processing events to making transformed data trustworthy. Chapter 10 focuses on data quality, modeling, tests, and semantic consistency so that both batch and streaming outputs can become reliable analytical products.