TuranMart’s analytical platform now has durable storage, lake zones, and a first warehouse-style sales mart. The next challenge is processing. Every night, operational systems export order lines, payment events, inventory snapshots, marketing costs, and clickstream summaries. Analysts expect the next morning’s dashboard to show trusted revenue by region and channel. Finance expects totals that reconcile with payment settlement. Supply-chain planners expect inventory aging and reorder suggestions before stores open.
Batch processing is the discipline that turns bounded data into repeatable analytical outputs. A batch has a start, an input boundary, a transformation plan, an output boundary, and a validation rule. It may process one CSV file on a laptop, a partitioned Parquet dataset in object storage, or terabytes of records across a Spark cluster. The scale changes, but the engineering questions remain the same: what is the input contract, what is the transformation, what is the output contract, and how do we know the run is correct?
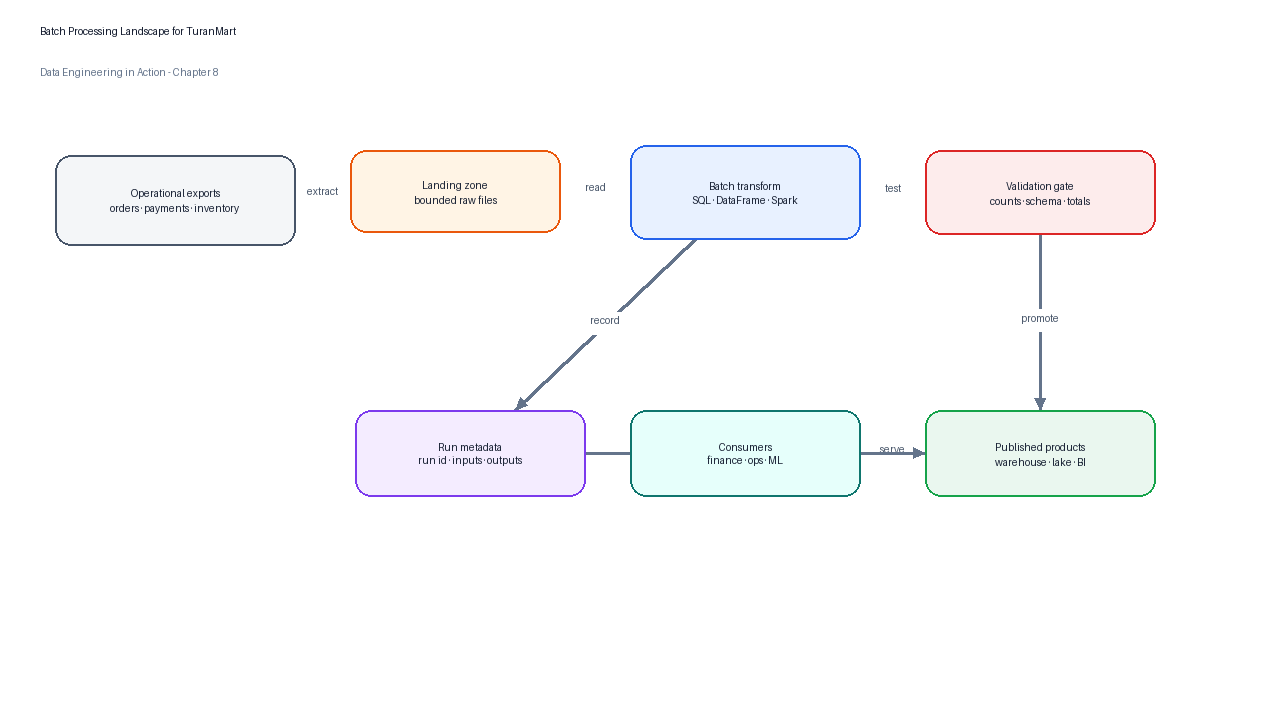
Figure 1:Batch processing converts bounded operational data into validated analytical products through ingestion, transformation, storage, quality checks, and publication.
Learning Objectives¶
By the end of this chapter, you will be able to explain where batch processing fits in a modern data platform, choose between Python scripts, pandas, DuckDB, and Spark for different batch workloads, design Parquet-based exchange contracts, reason about idempotent reruns and partitioned outputs, and build a deterministic local batch pipeline with validation.
| Skill | Why it matters in production |
|---|---|
| Define a batch boundary | Prevents partial inputs, duplicate processing, and ambiguous reruns. |
| Select the right processing tier | Keeps simple workloads simple while leaving a path to distributed scale. |
| Use Parquet intentionally | Preserves schema, compression, and columnar access across engines. |
| Design idempotent outputs | Allows safe retries, backfills, and recovery after failed runs. |
| Validate before publishing | Protects dashboards, finance reports, and downstream models from silent corruption. |
8.1 What Batch Processing Means¶
A batch job processes a bounded collection of records. The boundary may be a file, a database snapshot, a partition such as dt=2026-05-31, or a range of source-system transaction identifiers. Unlike streaming, which handles an unbounded flow of events, batch processing assumes that the job can reason about a finite input set and produce a finite output set.
Batch remains central even in companies that adopt real-time systems. Financial close, inventory reconciliation, customer lifetime value, historical model training, regulatory extracts, and dimensional warehouse loads are naturally batch-oriented. These workloads value completeness, repeatability, and auditability more than sub-second latency.
| Batch concept | Practical meaning at TuranMart |
|---|---|
| Input boundary | All order, payment, and shipment records for a business date. |
| Transformation plan | Cleansing, joining, aggregation, enrichment, and business-rule application. |
| Output boundary | A partitioned dataset, warehouse table, report extract, or model feature snapshot. |
| Run metadata | Run identifier, input partitions, row counts, checksums, code version, and status. |
| Validation gate | Tests that must pass before the output becomes visible to consumers. |
The simplest batch job is a script that reads yesterday’s CSV file and writes a summary. The most complex batch job may coordinate thousands of distributed tasks across a cluster. Both need the same operational discipline. The job should be idempotent, meaning that rerunning it for the same input boundary produces the same final output rather than appending duplicates or mixing old and new results.
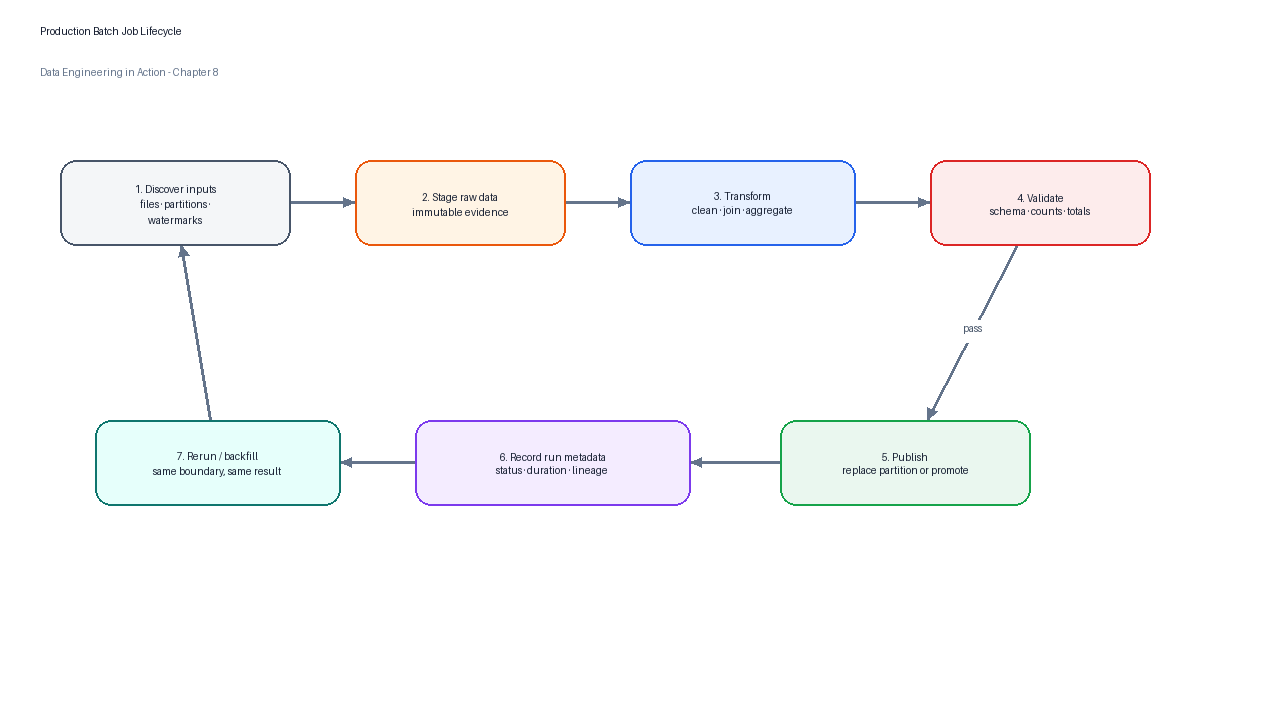
Figure 2:A reliable batch job follows a predictable lifecycle: discover inputs, stage raw data, transform, validate, publish, record metadata, and support reruns.
8.2 The Single-Machine Processing Ladder¶
Data engineers should not reach for a distributed cluster too early. Many valuable batch jobs begin on a single machine. A small export can be parsed with Python’s standard csv module, explored with pandas, and promoted into DuckDB when SQL, Parquet, and larger-than-memory file scans become important. This ladder is not a sign of immaturity; it is a disciplined way to keep complexity proportional to the problem.
8.2.1 Python csv for Small, Explicit File Work¶
CSV is still common because spreadsheets, databases, SaaS tools, and legacy systems can all produce it. Python’s standard library documents CSV as a common import and export format for spreadsheets and databases, while also warning that producers differ in delimiters, quoting, and dialects.[1] The csv module is useful when the job needs transparent row-by-row control, minimal dependencies, or strict handling of messy delimiter rules.
A CSV-only script should be explicit about encoding, newline handling, field names, required columns, and type conversion. The module returns strings by default, so production scripts should convert dates, amounts, booleans, and identifiers deliberately rather than assuming the file has already arrived in analytical form.[1]
Good use of csv | Poor use of csv |
|---|---|
| Validate a small supplier extract with known columns. | Join millions of rows across several files. |
| Convert a source export into a normalized staging file. | Implement complex analytical windows manually. |
| Stream through rows with constant memory. | Recreate a SQL optimizer in Python loops. |
8.2.2 pandas for In-Memory DataFrames¶
pandas is productive when a dataset fits comfortably in memory and the work benefits from DataFrame operations such as filtering, joins, group-by aggregation, reshaping, time-series handling, and plotting. Its user guide covers these areas as first-class topics, which is why pandas is a natural tool for analysis, prototyping, and small operational batch jobs.[2]
At TuranMart, pandas might be the right choice for reconciling a daily marketing-spend spreadsheet against a small channel dimension. It becomes the wrong choice when the input is a year of detailed clickstream events, when the job must run inside a constrained container, or when downstream teams need a SQL-readable Parquet dataset rather than a notebook result.
8.2.3 DuckDB for Local Analytical SQL¶
DuckDB occupies an important middle tier. It gives engineers SQL over local files, data frames, and columnar datasets without requiring a cluster. DuckDB documentation includes SQL, Python APIs, CSV and Parquet access, and integrations with pandas and Arrow, making it well suited for analytical batch processing on a developer machine or a modest server.[3]
DuckDB is especially helpful when a job starts as a prototype but needs a stronger contract. Instead of embedding business logic in many DataFrame method chains, an engineer can write readable SQL, materialize Parquet outputs, and validate row counts with repeatable queries. DuckDB can also read several Parquet files through lists or glob patterns and treat them as one table, which fits the partitioned data-lake style introduced in Chapter 6.[4]
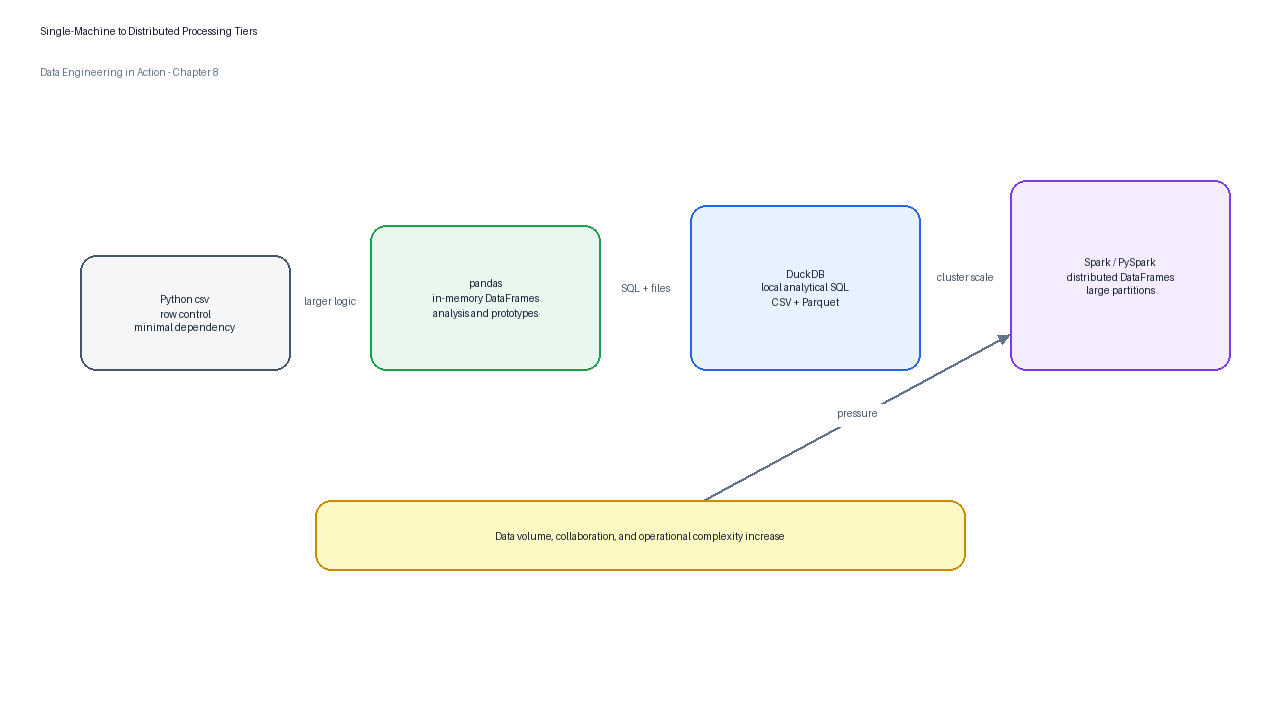
Figure 3:The processing ladder helps teams choose the simplest engine that satisfies data volume, transformation complexity, collaboration, and operational requirements.
| Tier | Typical scale | Strength | Watch-out |
|---|---|---|---|
Python csv | Kilobytes to low gigabytes when streaming | Precise row control with no third-party dependency. | Manual type handling and limited analytical expressiveness. |
| pandas | Megabytes to a few gigabytes in memory | Fast exploratory DataFrame development. | Memory pressure and notebook-to-production drift. |
| DuckDB | Local files from megabytes to many gigabytes | SQL over CSV, Parquet, pandas, and Arrow. | Single-node execution and local resource limits. |
| Spark | Large partitioned datasets across machines | Distributed execution, scheduling, and ecosystem integration. | Cluster complexity, shuffle costs, and operational overhead. |
8.3 Parquet as the Batch Exchange Contract¶
A batch pipeline needs a durable exchange format. CSV is easy to inspect, but it does not preserve rich types well, has weak schema contracts, and forces engines to read full rows even when only a few analytical columns are needed. Parquet is a better default for analytical batch outputs because it is columnar, compressible, and widely supported across engines. The Apache Parquet project maintains documentation and format resources for this file format ecosystem.[8]
DuckDB’s Parquet documentation describes Parquet files as compressed columnar files that are efficient to load and process.[4] It also describes projection pushdown, where only required columns are read, and filter pushdown, where predicates can be pushed into Parquet scans and sometimes skip file sections using metadata.[4] Those capabilities matter because most analytical queries do not need every column of every row.
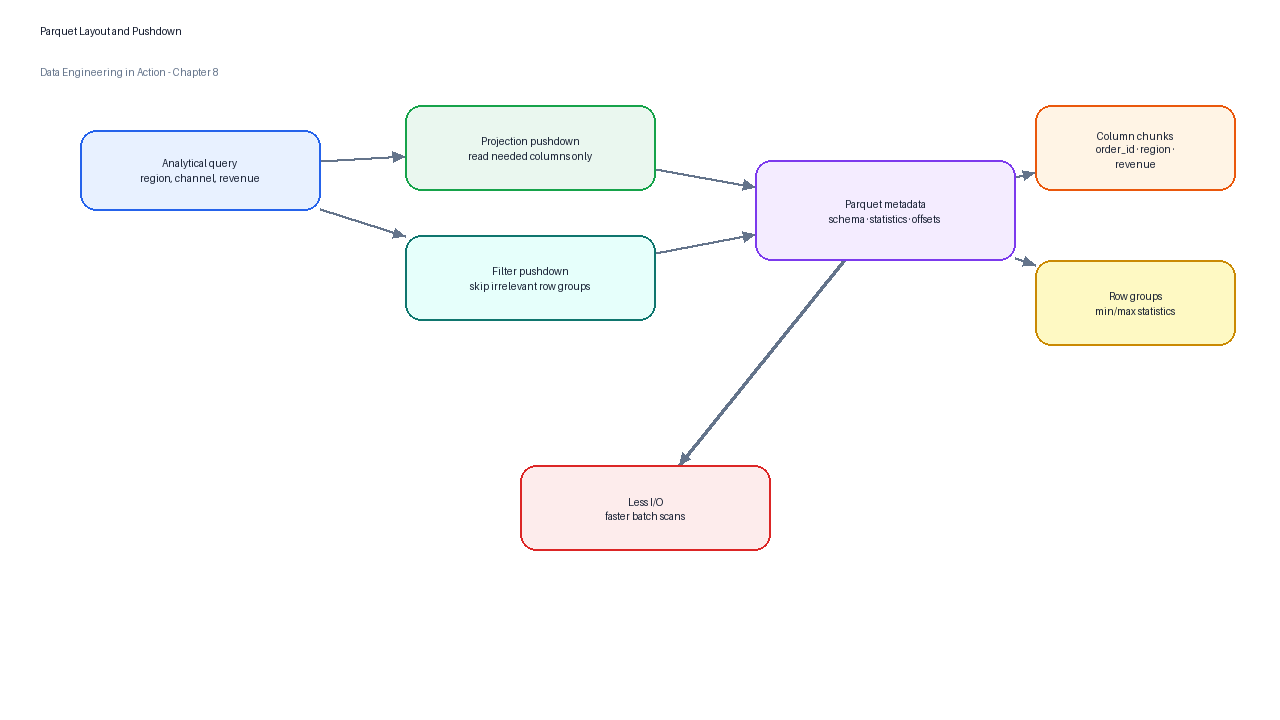
Figure 4:Parquet improves analytical batch processing by storing column chunks and metadata that allow engines to read only the columns and row groups required by a query.
Parquet is not magic. Dataset layout still matters. File counts, file sizes, compression choices, row-group sizes, partition columns, and schema evolution rules all affect performance and operability.[4] A partition strategy such as dt=2026-05-31/region=tashkent/ can make daily regional queries faster, but excessive partitioning can create too many small files. A production team should treat Parquet layout as an interface design problem rather than a storage afterthought.
| Design choice | Good default for Chapter 8 lab | Why it is reasonable |
|---|---|---|
| File format | Parquet for curated outputs | Preserves schema and supports columnar scans. |
| Raw interchange | CSV for small source exports | Mirrors common operational exports and is easy to inspect. |
| Partition key | Business date | Supports backfills and daily reruns. |
| Compression | Engine default or Snappy/Zstandard | Balances compatibility and storage efficiency. |
| Schema policy | Explicit columns and types | Prevents accidental drift from changing downstream reports. |
8.4 Distributed Batch with Spark and PySpark¶
Spark becomes attractive when the dataset is too large for one machine, when the processing must be parallelized across many files, or when the organization already operates a cluster platform. Apache Spark 4.0.1 documentation describes Spark running locally and on cluster managers such as Standalone, YARN, and Kubernetes.[5] PySpark is the Python API for Spark and is designed for large-scale distributed data processing while exposing Spark SQL, DataFrames, Structured Streaming, MLlib, and Spark Core.[6]
For batch data engineering, the most important Spark abstraction is often the DataFrame. Spark SQL documentation defines a DataFrame as a distributed collection organized into named columns, conceptually similar to a table in a relational database or a data frame in Python or R, but with richer optimizations under the hood.[7] PySpark documentation recommends DataFrames over the low-level RDD API for many workloads because DataFrames are easier to express and can benefit from Spark’s automatic query optimization.[6]
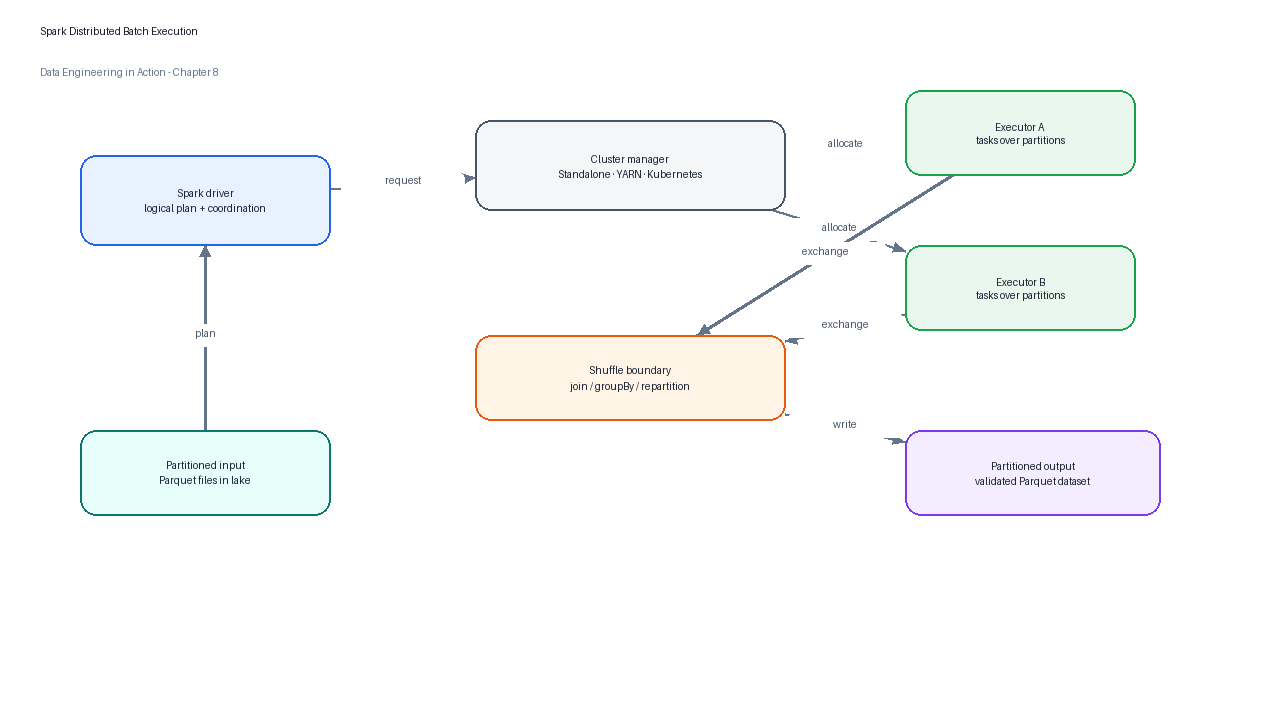
Figure 5:Spark distributes a batch job by planning work in the driver, assigning tasks to executors, shuffling data when required, and writing partitioned outputs.
Spark does not remove the need for design discipline. It makes some inefficient designs run at larger scale and exposes new failure modes: skewed keys, expensive shuffles, too many small files, insufficient executor memory, misconfigured partitions, and unbounded backfills. A good Spark job minimizes unnecessary shuffles, filters early, selects only needed columns, writes clear output partitions, and records run metadata.
| Spark concept | Practical interpretation |
|---|---|
| Driver | The process that builds the job plan and coordinates execution. |
| Executor | A worker process that runs tasks and stores intermediate data. |
| Partition | A unit of distributed data processed by a task. |
| Shuffle | Data movement across executors, often caused by joins, group-bys, and repartitioning. |
| DataFrame API | Structured transformations that Spark can optimize. |
spark-submit | Standard way to package and run Spark applications in production-like environments.[5] |
8.5 Scheduling, Reruns, and Operational Controls¶
A batch job becomes a production pipeline when it is scheduled, monitored, and recoverable. The scheduler might be cron for a small local job, a workflow orchestrator for a multi-step platform, or a managed cloud service. The tooling varies, but the contract is stable: a job should declare its inputs, outputs, dependencies, parameters, retry policy, and success criteria.
A daily TuranMart sales batch should not simply run “at midnight.” It should run after all required source exports for the business date have arrived, and it should fail closed if a required input is missing. The output should be written to a temporary location, validated, and then published atomically or near-atomically. If validation fails, consumers should continue seeing the previous trusted output rather than a partial new table.
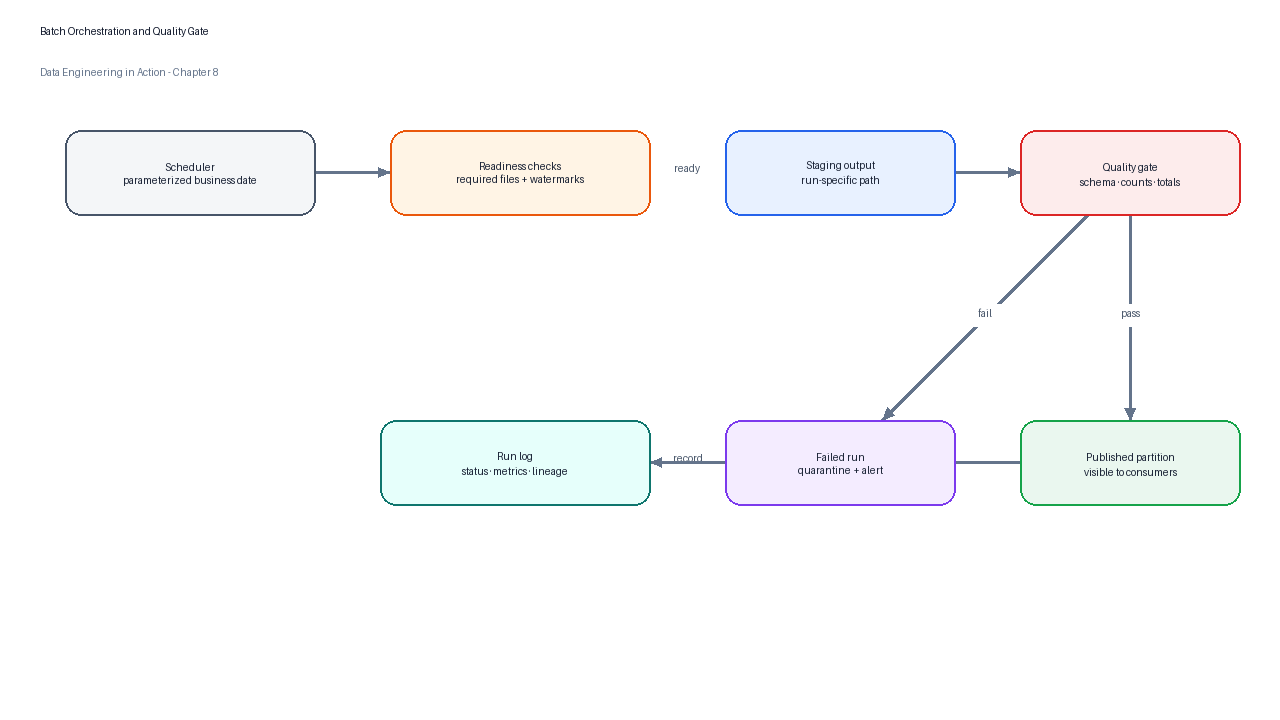
Figure 6:Production batch orchestration separates staging from publication so that only validated outputs become visible to downstream consumers.
| Control | Example implementation |
|---|---|
| Idempotent write | Delete and replace the target partition for the run date, or write to a run-specific staging path and promote after validation. |
| Input completeness | Check required source files, row counts, file checksums, and source-system watermarks. |
| Data quality | Validate schema, non-null keys, accepted values, row counts, and metric totals. |
| Observability | Record run duration, input counts, output counts, validation status, and error messages. |
| Backfill | Parameterize the business date and allow controlled reruns for historical partitions. |
| Ownership | Assign an accountable team, escalation route, and service-level expectation. |
8.6 Choosing the Right Batch Architecture¶
The right batch architecture is the simplest architecture that satisfies the workload’s correctness, scale, and operational needs. A daily executive dashboard over 50 MB of data does not need a cluster. A feature-generation job over five years of clickstream events probably does. A regulatory extract with strict audit requirements may prioritize deterministic run manifests more than raw speed.
TuranMart can use the following decision model. Begin with the input boundary and output contract, not the engine. If the data fits comfortably in memory and the transformation is simple, use pandas or a small script. If the transformation is SQL-heavy over files and needs Parquet output, use DuckDB. If the data is partitioned across many large files, requires distributed joins, or must integrate with cluster infrastructure, use Spark.
| Decision question | If yes, consider |
|---|---|
| Is the file small, row-oriented, and mostly needs validation or conversion? | Python csv. |
| Does the data fit in memory and benefit from DataFrame exploration? | pandas. |
| Is the workload analytical SQL over local CSV or Parquet files? | DuckDB. |
| Does the job scan or join large partitioned datasets across many machines? | Spark or PySpark. |
| Does the output become a governed table consumed by many teams? | Add orchestration, metadata, validation, and ownership regardless of engine. |
8.7 Guided Lab: Build a Deterministic TuranMart Batch Pipeline¶
In this lab, you will build a local batch pipeline for TuranMart’s daily commerce analytics. The lab starts with deterministic CSV source exports, uses DuckDB to normalize and aggregate the data, writes curated Parquet outputs, and validates exact row counts and metric totals. The goal is not to simulate every production feature. The goal is to practice the core batch pattern: read bounded inputs, transform with an explicit contract, write reproducible outputs, and validate before publication.
8.7.1 Lab Scenario¶
TuranMart receives three small daily exports. The order export contains order-line facts. The product export contains category metadata. The region export contains the mapping between stores and regions. The pipeline must calculate daily revenue by region and channel, category revenue, and a compact run manifest. All outputs must be deterministic so that the validator can compare them with expected fixtures.
| Asset | Path |
|---|---|
| Lab directory | shared/labs/ch08_batch_processing/ |
| Starter pipeline | shared/labs/ch08_batch_processing/starter.py |
| Validator | shared/labs/ch08_batch_processing/validator.py |
| Expected fixtures | shared/labs/ch08_batch_processing/expected_output.json |
| Solution guide | shared/solutions/ch08_batch_processing/solution.md |
8.7.2 Setup¶
Run the lab from the repository root or from the lab directory. The lab uses DuckDB and PyArrow so it can write and inspect Parquet files locally.
cd shared/labs/ch08_batch_processing
python3 -m pip install -r requirements.txt
python3 starter.py --business-date 2026-05-31
python3 validator.py --business-date 2026-05-318.7.3 What the Starter Pipeline Does¶
The starter pipeline creates a deterministic workspace under .batch/. It loads CSV files from data/raw/, registers them in DuckDB, casts business columns to explicit types, writes curated Parquet files under data/curated/, and writes report CSV files under data/reports/. It also writes a JSON manifest with the business date, input counts, output counts, and revenue totals.
raw CSV exports
-> DuckDB staging views
-> typed curated Parquet
-> daily region/channel report
-> category revenue report
-> manifest and validation8.7.4 Expected Output¶
A successful run prints a deterministic validation summary. Exact file paths can differ, but the counts and totals should match.
ORDERS rows: 8
CURATED orders rows: 8
REGION_CHANNEL rows: 5
CATEGORY rows: 4
TOTAL revenue: 682.50
VALIDATION PASSEDThe region-channel report should include the following business totals.
| business_date | region | channel | order_count | gross_revenue |
|---|---|---|---|---|
| 2026-05-31 | Almaty | marketplace | 2 | 148.00 |
| 2026-05-31 | Samarkand | mobile | 1 | 240.00 |
| 2026-05-31 | Tashkent | mobile | 2 | 151.50 |
| 2026-05-31 | Tashkent | web | 2 | 75.00 |
| 2026-05-31 | Bishkek | web | 1 | 68.00 |
8.7.5 Completion Checklist¶
You have completed the lab when the validator prints VALIDATION PASSED, the curated orders Parquet dataset contains eight rows, the daily region-channel report contains five rows, the total gross revenue equals 682.50, and rerunning the same command produces the same files rather than duplicate rows. You should also be able to explain why the job writes to a deterministic output path and why validation runs before publication.
8.7.6 Troubleshooting¶
| Symptom | Likely cause | Fix |
|---|---|---|
ModuleNotFoundError: duckdb | Requirements were not installed in the active Python environment. | Run python3 -m pip install -r requirements.txt from the lab directory. |
ModuleNotFoundError: pyarrow | Parquet support dependency is missing. | Reinstall requirements and confirm the active interpreter. |
| Validator reports wrong totals | Source CSV files were edited or stale outputs remain from a modified run. | Delete .batch/ and rerun starter.py. |
| Report row order differs | The query lost its deterministic ORDER BY. | Sort by business date, region, and channel before writing reports. |
| Duplicate rows appear after rerun | The pipeline appended to existing outputs. | Replace the run directory or target partition before writing new outputs. |
8.7.7 Cleanup¶
rm -rf .batchCommon Pitfalls¶
Batch pipelines fail most often at boundaries. A team may write correct transformation logic but process incomplete inputs, append duplicate outputs, publish before validation, or make the run impossible to reproduce. These failures are avoidable when engineers design the job as a contract rather than a script.
| Pitfall | Why it hurts | Better practice |
|---|---|---|
| Treating a schedule time as proof of input completeness | A source export can be late or partial. | Check files, watermarks, row counts, and expected partitions before transformation. |
| Appending reruns to the same output | Retries and backfills duplicate metrics. | Make writes idempotent by replacing the target partition or promoting a clean staging path. |
| Using CSV as the final analytical format | Types, compression, and column pruning are weak. | Use Parquet for curated analytical outputs. |
| Scaling to Spark too early | Cluster overhead hides simple logic and increases operating cost. | Use the smallest tier that satisfies scale and reliability requirements. |
| Ignoring shuffle and skew in Spark | One hot key can dominate runtime and cause task failures. | Inspect key distributions, partition deliberately, and reduce data before joins. |
| Publishing without validation | Broken data reaches dashboards and downstream models. | Make validation a required gate before publication. |
Mini-Capstone: Batch Architecture Decision Record for TuranMart¶
Write a two-page architecture decision record for TuranMart’s nightly commerce batch. Your record should define the input boundary, source readiness checks, processing engine, output format, partitioning strategy, validation tests, rerun policy, ownership, and migration trigger from DuckDB to Spark. The decision should be concrete enough that another engineer could operate the job during a late source export, a failed validation, or a historical backfill.
| Decision area | Minimum answer required |
|---|---|
| Input boundary | Business date, required source datasets, and completeness criteria. |
| Engine choice | Python, pandas, DuckDB, or Spark with justification. |
| Output contract | File format, schema, partitioning, and publication location. |
| Idempotency | Exact rerun behavior for the same business date. |
| Validation | Required schema, count, uniqueness, accepted-value, and metric-total checks. |
| Operations | Schedule, retry policy, monitoring, owner, and escalation route. |
| Migration trigger | Conditions that would justify moving to Spark or a managed workflow orchestrator. |
Exercises¶
| Difficulty | Exercise | Expected result |
|---|---|---|
| Easy | Add a new valid order line to the raw order CSV. | The curated row count and revenue total increase predictably after rerun. |
| Medium | Add a source readiness check that fails when a required CSV file is missing. | The pipeline stops before writing outputs and records a clear error. |
| Medium | Write the category report as Parquet as well as CSV. | The validator can read the Parquet report and confirm the same category totals. |
| Challenge | Parameterize the lab for a second business date and partition outputs by date. | Two dates can be processed independently without overwriting each other. |
| Team | Design the Spark version of the same pipeline for one year of order-line data. | The team can explain partitioning, shuffles, joins, validation, and publication semantics. |
Review Questions¶
| Question | What a strong answer should include |
|---|---|
| What distinguishes batch processing from streaming? | Batch processes bounded inputs and produces finite outputs, while streaming processes unbounded event flows continuously. |
| Why should a batch job be idempotent? | Safe retries and backfills require the same input boundary to produce the same final output without duplicates. |
When is Python’s csv module enough? | When the data is small or streamed row by row and the task mainly needs explicit parsing, validation, or conversion. |
| When does DuckDB become a better fit than pandas? | When SQL over local files, Parquet output, larger-than-memory scans, or reproducible analytical queries matter. |
| Why is Parquet preferred for curated analytical batch outputs? | It preserves typed columnar data, supports compression, and enables projection and filter pushdown in capable engines. |
| What makes Spark suitable for large batch workloads? | It distributes DataFrame computations across executors and integrates with cluster managers and large partitioned datasets. |
| What should happen when validation fails? | The new output should not be published; the run should fail clearly while consumers continue using the last trusted output. |
Summary¶
Batch processing turns bounded operational data into trustworthy analytical products. It remains essential for daily reporting, reconciliation, historical backfills, warehouse loading, and feature generation. The engineering discipline is not defined by a single tool. It is defined by clear input boundaries, explicit transformation logic, deterministic output contracts, validation, metadata, and recoverable operations.
The practical processing ladder begins with Python csv for explicit small-file work, moves to pandas for in-memory DataFrame analysis, advances to DuckDB for local analytical SQL over files and Parquet, and reaches Spark when distributed execution is justified. Parquet serves as the common exchange format that lets these tiers cooperate. In the next chapter, the book moves from bounded batch inputs to streaming systems, where Kafka and Flink process events that continue arriving after the job starts.