Part 1: The Triple Threat: Embedding, Reranking, and Invoking
1.1 Introduction to Embedding, Reranking, and Qwen3 Models
Introduction to Embedding and Reranking
Text embedding and reranking are foundational technologies in natural language processing (NLP) that power modern search engines, recommendation systems, retrieval-augmented generation (RAG) pipelines, and even an Agentic AI.
Text Embedding: Text embeddings convert unstructured text into dense numerical vectors (e.g., arrays of numbers) that capture semantic meanings. These vectors enable machines to measure the similarity between texts, supporting tasks such as semantic search, clustering, and classification. For example, a query like “best LLM for the finance industry” can be matched to LLM (Large Language Model) descriptions or articles that align with its intent.
Reranking: Reranking refines the results of an initial retrieval step by reordering candidates based on finer-grained relevance scores. While embedding models retrieve broad matches, rerankers prioritize the most contextually relevant results. For instance, a search engine might first retrieve 100 documents using embeddings, then apply a reranker to pick the top 10 most relevant ones.
Key Applications:
Web search and recommendation systems
Legal document analysis and compliance monitoring
Healthcare research (e.g., finding clinical trials for a drug)
The Qwen3 Embedding series, built on the Qwen3 models, represents a leap forward in text representation learning. It includes embedding models (for vectorizing text) and reranking models (for refining search results), with parameter sizes of 0.6B, 4B, and 8B.
Key Features
Exceptional Versatility:
State-of-the-art results on benchmarks like MTEB (Multilingual Text Embedding Benchmark) and MTEB-Code.
Excelling in cross-lingual and code retrieval tasks (e.g., searching GitHub repositories for Python functions).
2. Comprehensive Flexibility:
Model Sizes: 0.6B (lightweight), 4B (balanced), and 8B (high-performance).
Customizable Dimensions: Variable vector lengths (e.g., 1024D for Qwen3-Embedding-0.6B, 4096D for Qwen3-Embedding-8B).
Instruction Awareness: Task-specific instructions (e.g., “Given the following question, facts, and contexts, retrieve the correct answer.”).
3. Multilingual Mastery:
Supporting 100+ languages, including programming languages (Python, Java, C++, etc.).
Handling cross-lingual tasks (e.g., querying in English and retrieving French documents).
Evaluation results
Evaluation results for reranking models:
Evaluation results for reranking models:
Advantages
Performance:
Qwen3-Embedding-8B scores 70.58 on MTEB Multilingual, outperforming Google’s Gemini-Embedding.
Qwen3-Reranker-8B improves ranking accuracy by 3.0 points over smaller rerankers.
Efficiency:
Smaller models (such as 0.6B) strike a balance between speed and accuracy in resource-constrained environments.
Customization:
Users can customize instruction templates for domain-specific tasks (e.g., legal contract analysis).
Disadvantages
Resource Requirements:
Larger models (such as 8B) demand significant GPU memory (e.g., 8x NVIDIA A100s for training).
Latency:
High-performance rerankers may cause delays in real-time applications (e.g., live chatbots).
Technical Specifications
Note: “MRL Support” indicates whether the embedding model supports custom dimensions for the final embedding. “Instruction Aware” notes whether the embedding or reranking model supports customizing the input instruction for different tasks.
1.2. Deploying and Invoking Embedding Models on Alibaba Cloud
Deploying Qwen3 on PAI-EAS and Using OpenAI-Compatible Libraries
Alibaba Cloud provides two primary methods to invoke embedding models:
Model Studio: A no-code platform offering ready-to-use models like text-embedding-v3 (ideal for quick deployment). Visit Alibaba Cloud Model Studio for more details.
PAI-EAS: A managed service for deploying custom models like Qwen3-Embedding-8B (for advanced customization). Visit PAI — Platform for AI for more details.
Method 1: Using Model Studio for Text Embedding
Alibaba Cloud’s Model Studio simplifies access to pre-trained open-sourced and proprietary models, including text-embedding-v3, without requiring deployment or infrastructure management.
Click the “Docs” tab in the top navigation bar (highlighted in red in the image).
Click “Embedding” (highlighted in red in the image). This will display the embedding-related documentation.
Invoke the Model via OpenAI-Compatible API:
Once selected, navigate to the “API Details” tab to obtain the endpoint and authentication credentials.
Example request format for generating embeddings:
import os from openai import OpenAI
client = OpenAI( api_key=os.getenv("DASHSCOPE_API_KEY"), # Replace with your API Key if you have not configured environment variables base_url="https://dashscope-intl.aliyuncs.com/compatible-mode/v1" # base_url for Model Studio ) completion = client.embeddings.create( model="text-embedding-v3", input='The quality of the clothes is excellent, very beautiful, worth the wait, I like it and will buy here again', dimensions=1024, encoding_format="float" ) print(completion.model_dump_json())
Benefits of Model Studio
No Deployment Required: Use pre-trained models instantly.
Scalability: Pay-as-you-go pricing with automatic scaling.
Ease of Use: Ideal for developers unfamiliar with setting up infrastructures.
Method 2: Deploying Qwen3 Embedding Models on PAI-EAS
For advanced use cases requiring customization (e.g., domain-specific fine-tuning), deploy Qwen3-Embedding-8B or other Qwen3 variants on PAI-EAS (Elastic Accelerated Service). Below is a step-by-step guide based on the latest PAI tools and interfaces:
2. Select workspaces, and choose QuickStart >Model Gallery > NLP > embedding, find or search for Qwen3-Embedding models.
3. Click Deploy next to the desired model (e.g., Qwen3-Embedding-8B).
4. Configure instance type, auto-scaling, and other parameters.
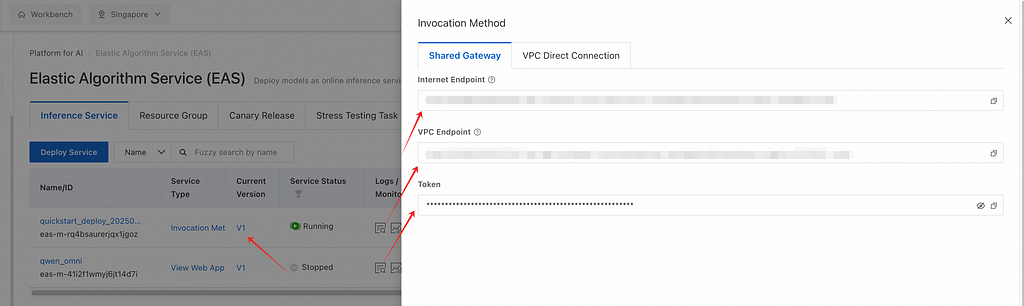
5. To access the recently deployed model, navigate to the Model Deployment section and select Elastic Algorithm Service (EAS). Once the “Service Status” is “Running”, you will be able to start using the model.
6. Click Invocation Method and copy the generated API endpoint for integration.
This streamlined workflow ensures rapid deployment while maintaining flexibility for advanced customization.
Send Requests via OpenAI-Compatible API
PAI-EAS natively supports OpenAI’s API format, enabling seamless integration with tools like langchain or openai:
from openai import OpenAI
# Initialize client with PAI-EAS endpoint client = OpenAI( base_url="https://<pai-eas-endpoint>/v1", api_key="<your-pai-api-key>" ) # Generate embeddings embedding = client.embeddings.create( input="How should I choose best LLM for the finance industry?", model="qwen3-embedding-8b" ) print(embedding.data[0].embedding) # Outputs a 4096D vector # Rerank search results rerank = client.rerank.create( query="Renewable energy solutions", documents=[ "Solar power adoption surged by 30% in 2024.", "Wind energy faces challenges in urban areas.", "Hydrogen fuel cells offer zero-emission transportation." ], model="qwen3-reranker-4b" ) print(rerank.results) # Returns relevance scores
Direct API Calls (Optional) For low-level control, send raw HTTP requests:
Qwen3’s embedding and reranking models offer unparalleled flexibility and performance across industries. By leveraging Alibaba Cloud’s PAI ecosystem, you can deploy and fine-tune these models to address domain-specific challenges, from financial risk analysis to medical research. Future work includes expanding multimodal capabilities (e.g., cross-modal retrieval of images and text) and optimizing for edge devices.
Part 2: Fine-Tuning Qwen3 on PAI-Lingjun and Industry Use Cases
In the world of AI, one size does not fit all. While Qwen3’s embedding and reranking models are pre-trained to master general tasks — from multilingual text understanding to code retrieval — their true potential shines when tailored to domains like finance, healthcare, or law. This is where PAI-Lingjun, Alibaba Cloud’s large-scale training platform, steps in as the catalyst for transformation.
The Need for Customization
Imagine a pharmaceutical researcher sifting through millions of clinical trials to find a match for a rare disease, or a lawyer scanning thousands of contracts for a specific clause. Generic models, while powerful, often miss the subtleties of domain-specific language — terms like “EBITDA,” “myocardial infarction,” or “force majeure” demand precision. Fine-tuning bridges this gap, adapting Qwen3’s architecture to grasp the nuances of specialized tasks, from drug discovery to financial risk assessment.
PAI-Lingjun: The Engine Behind Precision
PAI-Lingjun is a powerhouse designed to handle the computational demands of refining Qwen3 models. With support for distributed training across GPUs/TPUs, it enables organizations to scale from 0.6B to 8B parameter models, ensuring even the most complex domains can find their ideal balance between speed and accuracy.
Key Components of the Workflow:
Data as the Foundation: Domain-specific success begins with curated data. For finance, this might mean SEC filings; for healthcare, it’s clinical notes and research papers. The richer the dataset, the deeper the model’s understanding.
Synthetic Brilliance: Qwen3’s text generation capabilities create synthetic data at scale — 150 million text pairs across languages — filling gaps where labeled data falls short.
Staged Mastery: Training unfolds in phases. First, weakly supervised pretraining establishes a broad foundation; then, high-quality labeled data refines the focus. Finally, model merging combines checkpoints, enhancing robustness like a symphony conductor harmonizing instruments.
The Art of Training: A Multi-Stage Symphony
Weakly Supervised Pretraining: Here, Qwen3 learns the rhythm of a domain. By generating synthetic data — like crafting queries for loan applications or mimicking legal jargon — it builds a scaffold of understanding, even in low-resource scenarios.
Supervised Fine-Tuning: With curated data, the model hones its expertise. A bank might train on 12 million financial documents, teaching it to spot red flags in loan applications with surgical precision.
Model Merging: Like blending colors on a palette, spherical linear interpolation (SLERP) merges checkpoints, balancing generalization and specialization. The result? A model that thrives in both breadth and depth.
Resource Realities: Powering the Transformation
Fine-tuning Qwen3-Embedding-8B isn’t for the faint of heart. It demands 8x NVIDIA A100 GPUs and 3–5 days of training time. Yet, the payoff is monumental: retrieval accuracy jumps from 72% to 89%, and domain coverage soars to 93%. Smaller models, like Qwen3-Reranker-0.6B, offer agility for real-time scoring, proving that power isn’t always about size.
2.2. Industry Use Cases: Transforming AI Across Verticals
1. Healthcare: Accelerating Medical Research
Challenge: Researchers struggle to find clinical trials for rare diseases, such as cystic fibrosis.
Solution:
Index PubMed abstracts and arXiv papers using Qwen3-Embedding.
Deploy Qwen3-Reranker to prioritize trials matching patient genotypes.
2. Legal: Revolutionizing Contract Analysis
Challenge: Law firms need to identify clauses like “non-compete agreements” in contracts.
Solution:
Fine-tune Qwen3 on legal corpora (e.g., SEC filings, court rulings).
Use rerankers to highlight clauses relevant to mergers and acquisitions.
3. E-Commerce: Hyper-Personalized Product Search
Challenge: Users searching for “wireless Bluetooth headphones” get irrelevant results.
Solution:
Train Qwen3-Embedding on product catalogs and customer reviews.
Apply rerankers to boost items with matching features (e.g., noise cancellation).
4. Finance: Precision Risk Assessment
Challenge: Banks must flag high-risk loan applications with red flags (e.g., delinquency history).
Solution:
Deploy Qwen3-Embedding to vectorize applications.
Use Qwen3-Reranker to score risk factors against regulatory guidelines.
5. Chemistry: Next-Gen Drug Discovery
Challenge: Scientists need to find molecules similar to a target compound.
Solution:
Train Qwen3 on chemical patents and PubChem data.
Embed molecular structures (e.g., SMILES strings) for similarity searches.
2.3. Ready to Build Your Domain-Specific AI?
With PAI-Lingjun and Qwen3, the power to transform industries is at your fingertips. Whether you’re optimizing financial risk models or accelerating medical breakthroughs, Qwen3’s embedding and reranking capabilities deliver unmatched precision. Let’s redefine what’s possible — together.
Got questions? Reach out to our team or explore the PAI-Lingjun to start your free trial today!
Conclusion: Your Domain, Our Expertise
Fine-tuning Qwen3 is not just a technical process — it’s a strategic leap. Whether you’re revolutionizing finance, healthcare, or materials science, PAI-Lingjun equips you to unlock AI’s full potential.
Part 3: Advanced Deployment Strategies and Optimization Techniques
3.1. Future Directions for Qwen3 Embedding Models
The Qwen3 Embedding series represents a significant leap in text representation learning. However, ongoing advancements in large language models (LLMs) open new frontiers. Below are key areas of focus for future development, emphasizing instruction-aware embeddings and MRL (Matryoshka Representation Learning):
1. Instruction-Aware Embeddings
Traditional models require retraining to adapt to new tasks, but Qwen3’s instruction-aware architecture allows dynamic adaptation through task-specific prompts. This eliminates the need for domain-specific fine-tuning, reducing costs and complexity.
Key Concepts:
Instruction-Aware Design: Qwen3 Embedding models accept explicit instructions as input, guiding the model to generate embeddings tailored to specific tasks. For example:
# Example: Flag loan applications with geopolitical risk factors task = "Identify loan applications with geopolitical risk factors" query = "Loan application for a tech firm in Southeast Asia" input_text = get_detailed_instruct(task, query)
This method embeds the instruction into the input context, ensuring the model focuses on domain-specific nuances (e.g., “geopolitical risk”) without requiring retraining.
Few-Shot Adaptation: By appending task-specific instructions to queries, Qwen3 can adapt to new domains with minimal labeled data. For instance, a chemistry reranker can prioritize molecules relevant to a specific drug target by including an instruction like:
task = "Find molecules similar to aspirin for anti-inflammatory use" query = "C1CC(=O)NC(=O)C1" # Aspirin's SMILES string
2. MRL (Matryoshka Representation Learning)
MRL enables dynamic adjustment of embedding dimensions during inference, offering flexibility without retraining. This innovation allows a single model to serve multiple scenarios (e.g., lightweight edge devices vs. high-precision servers).
How MRL Works:
Variable Output Dimensions: Qwen3 Embedding models generate embeddings with customizable dimensions (e.g., 1024D, 2560D, or 4096D).
Dynamic Adjustment: During inference, you can specify the desired dimension via the output_dimension parameter:
# Generate a 2560D vector for financial risk analysis embeddings = model.encode(queries, output_dimension=2560)
Advantages of MRL:
Resource Efficiency: Lower-dimensional embeddings (e.g., 1024D) for edge devices and higher dimensions (e.g., 4096D) for server-grade applications.
Scalability: A single model can be deployed across diverse use cases (e.g., semantic search and molecular similarity).
Future-Proofing: Easy adaptation to evolving requirements (e.g., increasing dimensionality as hardware improves).
Example: MRL in Healthcare A pharmaceutical researcher can generate 4096D embeddings for precise molecule screening but switch to 1024D for real-time patient record clustering:
Instruction-Aware Embedding: Include instructions like “Prioritize Python implementations of Dijkstra’s algorithm.”
MRL for Efficiency: Use 1024D embeddings for quick searches and 4096D for precision.
Benchmark Results:
Why Instruction-Awareness and MRL Outperform Fine-Tuning
1. Instruction-Aware Embedding: Dynamic Adaptation Without Retraining
Problem: Traditional fine-tuning requires retraining for each domain, which is time-consuming and resource-intensive.
Solution: Qwen3’s instruction-aware design allows developers to define task-specific instructions at inference time.
Legal: “Highlight clauses related to non-compete agreements.”
E-Commerce: “Boost items with noise cancellation features.”
Benefits:
Zero-Shot Adaptation: No need for domain-specific training data.
Cost Savings: Avoid the expense of retraining models for every use case.
2. MRL: Flexible Dimensions for Any Scenario
Problem: Fixed-dimension embeddings (e.g., 768D) force trade-offs between accuracy and efficiency.
Solution: MRL allows dynamic adjustment of dimensions.
Edge Devices: Use 1024D embeddings for fast, low-memory inference.
High-Precision Tasks: Switch to 4096D for complex tasks like drug discovery.
Benefits:
Single Model, Multiple Use Cases: Eliminate the need for multiple models.
Future-Proofing: Scale dimensionality as hardware evolves without retraining.
Conclusion: Instruction-Awareness and MRL — The New Paradigm
Qwen3 Embedding models redefine flexibility by combining instruction-aware embeddings and MRL Support, eliminating the need for domain-specific fine-tuning.
Instruction-Aware Embeddings enable developers to customize model behavior through task-specific prompts, thereby reducing the reliance on retraining.
MRL Support enables dynamic dimension adjustment, ensuring optimal performance across edge and cloud deployments.
By leveraging these innovations, organizations can:
Reduce Costs: Avoid expensive fine-tuning cycles.
Accelerate Deployment: Adapt models to new domains in minutes, not months.
Future-Proof Systems: Scale dimensionality as hardware improves.
Final Thoughts: The Genetic Code of Meaning Unveiled
For the first time in history, machines can decode the genetic relationships between a Sanskrit poem, a Python function, and a medical diagnosis — a breakthrough made accessible to all through open-source innovation. Just as DNA sequencing revolutionized biology by revealing the universal code of life, Qwen3 Embedding transforms AI by mapping the molecular structure of meaning itself. This technology transcends language, culture, and discipline, uncovering hidden connections that redefine how AI systems understand and retrieve information.
A Paradigm Shift in Understanding
Traditional AI search operates like a keyword-matching robot, confined to surface-level text matches. Qwen3 Embedding, however, functions as a DNA sequencer for language, capturing the deep, semantic relationships between concepts across 250+ languages and programming paradigms. Whether analyzing a medical diagnosis, a legal contract, or a quantum computing algorithm, Qwen3 deciphers the genetic code of meaning, enabling machines to grasp nuance, context, and interdisciplinary links. This isn’t just an incremental improvement — it’s a paradigm shift.
Technical Mastery and Open-Source Democratization
Qwen3 Embedding’s multi-stage training pipeline combines synthetic data generation, supervised fine-tuning, and model merging to achieve state-of-the-art performance. With scores of 70.58 on MTEB Multilingual and 80.68 on MTEB Code, Qwen3 surpasses proprietary giants like Google’s Gemini-Embedding, proving that open-source innovation can outpace closed ecosystems. By open-sourcing the models under the Apache 2.0 license, Alibaba democratizes access to this “genetic code of meaning,” empowering developers worldwide to build more intelligent, more intuitive systems.
Beyond Benchmarks: Real-World Impact
The true power of Qwen3 lies not just in its technical specs but in its ability to bridge worlds:
Healthcare: Accelerating drug discovery by linking molecular structures to clinical trials.
Law: Automating clause analysis across multilingual contracts.
Finance: Flagging risks with precision by parsing global regulatory texts.
Education: Connecting interdisciplinary knowledge for personalized learning.
Chemistry: Revolutionizing material science by mapping molecular properties.
These are not hypothetical scenarios — they are realities already being shaped by Qwen3’s genetic-level understanding of meaning.
The Future: From Genetic Code to Intelligent Evolution
As AI evolves, Qwen3 Embedding sets the stage for multimodal systems that decode not just text but images, audio, and video through the same genetic lens. Imagine an AI that understands a biomedical paper, visualizes its implications in a 3D protein model, and generates code to simulate its behavior — all through unified, cross-modal embeddings.
Moreover, Qwen3’s efficiency, ranging from lightweight 0.6B models to high-performance 8B variants, ensures adaptability for both edge devices and cloud-scale applications. The future belongs to systems that learn like organisms, evolving through exposure to diverse data ecosystems. Qwen3 Embedding is not just a tool; it is the blueprint for this evolution.
Join the Revolution
The genetic code of meaning is now within reach. Explore Qwen3 Embedding and Reranking models on Hugging Face and ModelScope. Deploy them on Alibaba Cloud’s PAI ecosystem, or fine-tune them for your niche domain. Whether you’re a researcher, developer, or enterprise, the era of genetic AI understanding begins today.